artwork by Gemini 3 Pro
AI Playtesting - When Your Board Game Tests Itself
Game Architecture
Part 9 of 9A designer types “test my game for balance issues” into Nova. Moments later, they receive a structured critique: which player seat has an unfair advantage, whether the game rewards strategic play, and three intervention options. No prototyping, no recruiting playtesters, no spreadsheets. Just a conversation, and a feedback loop that runs every time you change a number. This is the story of how we taught a system to play board games, what failed spectacularly, and what that failure accidentally invented.
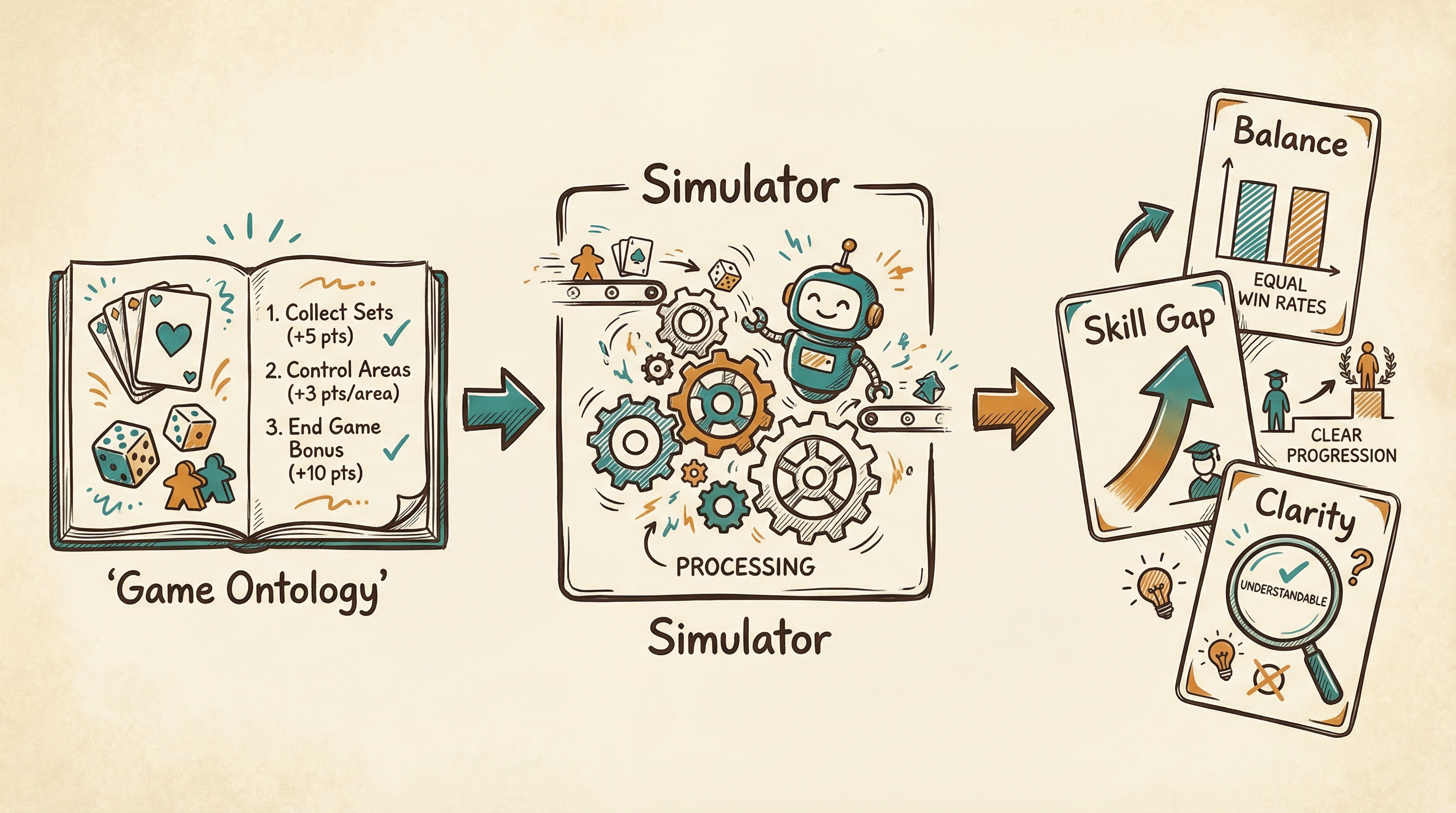
Figure. The automated playtesting pipeline transforms a structured game ontology into automated balance analysis, skill gap measurement, and rule clarity scores, all through a conversation with Nova.
This is Part 9 of the Game Architecture series. In Part 5, we demonstrated structured game generation. In Part 6, we explored the theory behind generative ontology. In Part 7, we introduced Nova, the conversational AI co-designer. And in Part 8, we showed the full pipeline from knowledge to creation.
But there was a gap. GameGrammar could generate a structurally valid game in minutes. Nova could help you refine it over sessions. Yet between “a design exists on paper” and “we know if it works at the table” sat the same wall every designer faces: prototype it, recruit friends, schedule sessions, track results by hand, and repeat the whole process after every change.
This article is about how we tore down that wall.
The Wall: Where Designs Go to Die
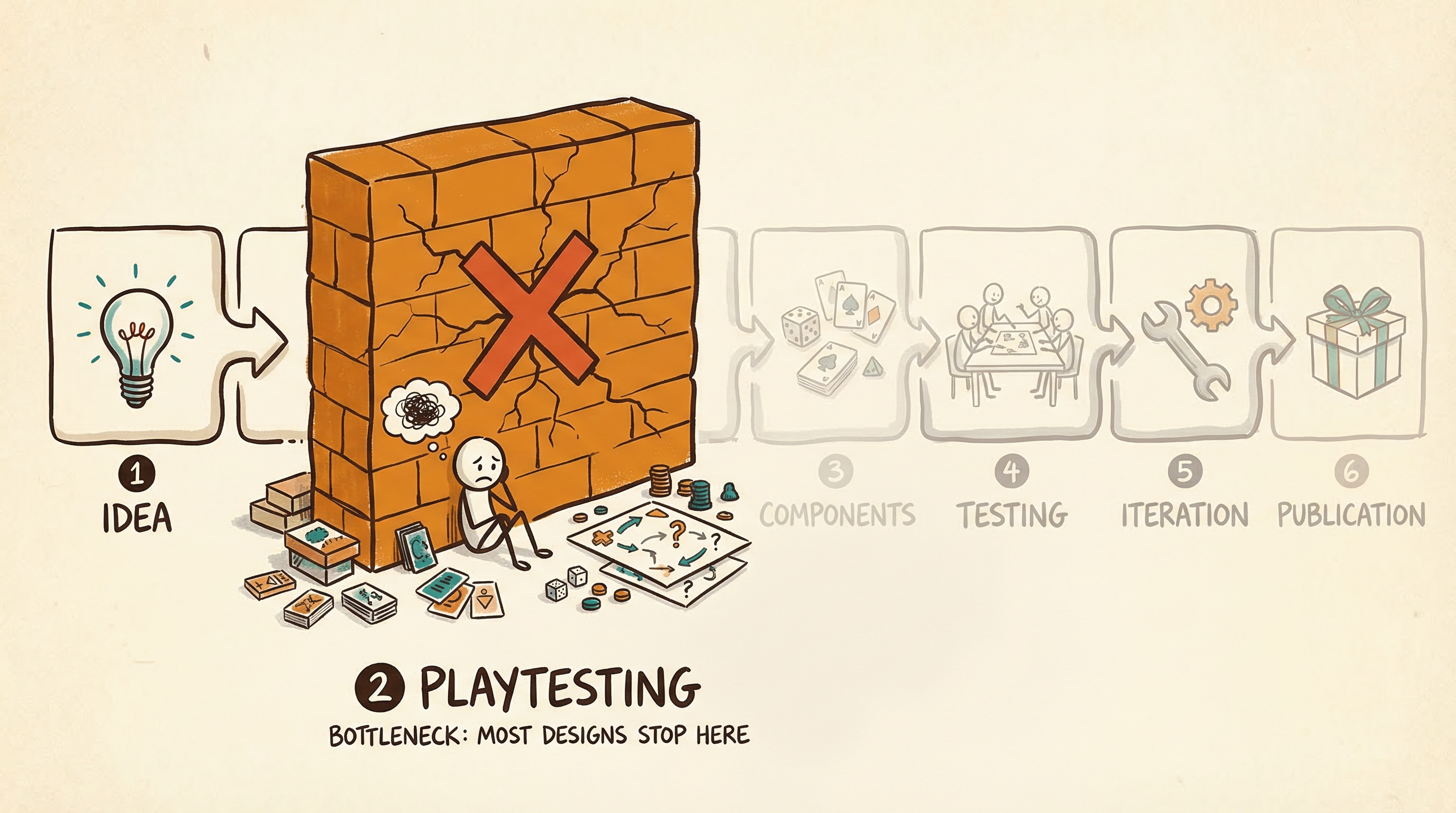
Figure. The board game design pipeline has nine stages. Stage 2 (iterative playtesting) is where most amateur designs stall.
Every game designer knows the feeling. You have spent a weekend crafting a deck-building game with a push-your-luck mechanism. The card types feel right. The economy seems balanced. The theme sings. Then reality hits: you need to print cards, recruit four friends who are free on the same evening, explain the rules, play through three sessions, take notes, change the numbers, and do it all again. By the third iteration, your friends are politely unavailable, and the game sits in a drawer.
The board game design pipeline has a well-known bottleneck, and it is not creativity. The tools for generating ideas, sketching mechanisms, even producing complete game ontologies, have accelerated dramatically. But determining whether a design is balanced and strategically interesting still requires physical prototyping, player recruitment, observation, and post-session analysis. This process spans weeks to months. It is where most amateur designs stall, and even professional studios spend the majority of their development time [1].
GameGrammar’s ontology pipeline had already automated concept generation, structural analysis, and conversational co-design via Nova. But the ontology output contains everything a simulator would need. Component specifications define the game objects. Mechanism details define the legal actions. Scoring formulas define how you win. Balance parameters define the constraints. Game arc defines the turn structure.
The data was there. The question was whether it could be made executable. It turns out, it can. Before we explain how, let us show you what it looks like in practice.
How Designers Use It: A Conversation with Nova
The entire playtesting pipeline surfaces through Nova, the conversational co-designer we introduced in Part 7. The designer never sees parsers, agents, or metrics directly. They see a conversation.
Video. GameGrammar AI Playtesting: Nova orchestrates the entire playtest pipeline from a natural language request.
The Design Loop
- The designer says: “Run a balance playtesting for the game”
- Nova parses the game rules, simulates 50 games with random agents, and analyzes the results
- Nova presents a structured critique with a reasoning chain: conclusion (“Love Letter shows a significant first-player advantage”), observation, data, mechanism explanation, and competitive impact
- Decision levels appear: Structural (Restructure) suggestions like rotating first player, Tuning suggestions like adjusting card values, and Fork to explore alternative designs
- The designer picks an intervention, Nova proposes the ontology change, and re-runs the playtest to verify the fix
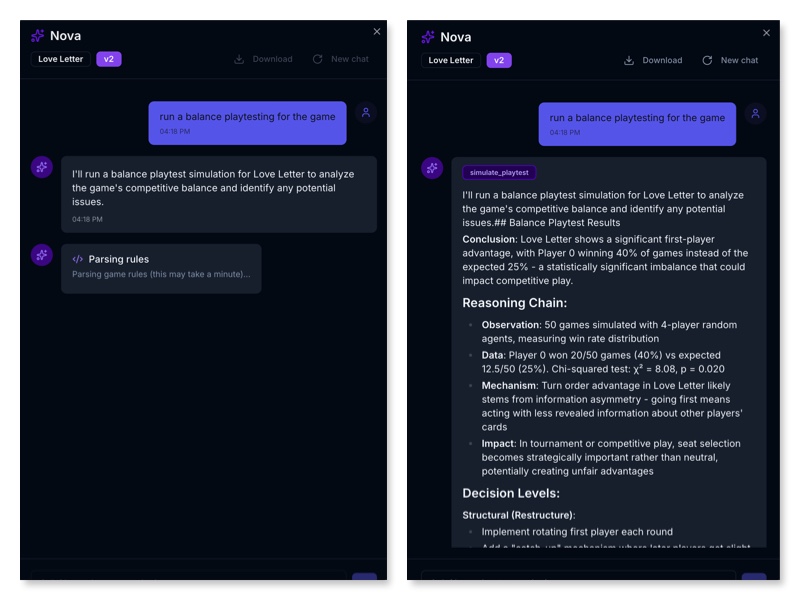
Figure. Nova presenting playtesting results inside GameGrammar. The critique reasoning chain surfaces balance findings, skill gap measurement, and intervention options through natural conversation.
Compare that to the traditional workflow: change a number, reprint the cards, recruit players, schedule an evening, play through, take notes, aggregate results. What used to be a multi-week iteration cycle becomes a continuous feedback loop inside a single conversation.
The Playtest History
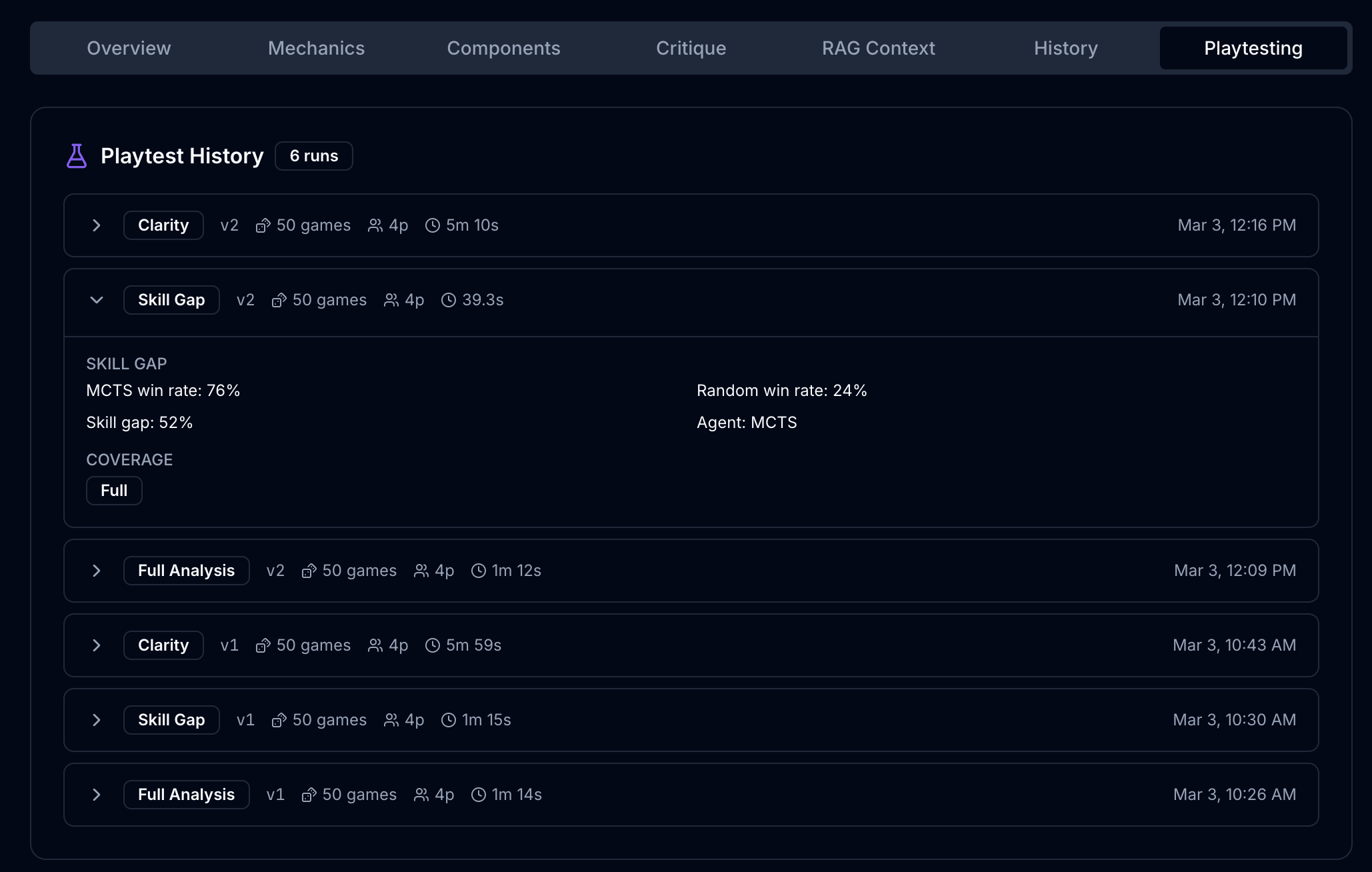
Figure. The Playtesting tab shows run history with expandable game logs. Designers can track how balance metrics evolve across design iterations.
Every playtest run is saved with its metrics, and designers can track how their balance numbers change across design iterations. Did that scoring tweak fix the first-player advantage? Did adding an extra card to the starting hand reduce stalemates? The history provides a quantitative record of design decisions and their measured impact.
Now that you have seen what the experience looks like, let us explore how it works under the hood.
The Approach: LLM Translates, Algorithms Play
We explored three approaches before arriving at the production system. A quick summary of the two that did not win, and why they still matter.
A direct simulator parsed the ontology into a deterministic game engine. It worked well for card games and found real balance signals on day one, but pattern-matching parsers break on anything beyond simple mechanics. The parser, not the game, becomes the bottleneck.
Letting an LLM play the game sounded promising: feed the ontology and game state to an LLM each turn, let it choose an action, no formal rules needed. We built seven player archetypes (aggressive, cautious, engine-builder, newbie, and others). But across every extended experiment, LLM agents performed worse than random (-39% skill gap after 100 games). This corroborates findings from GameBench [2] and GTBench [3]. LLMs cannot maintain consistent strategic reasoning over multiple turns [4]. However, the failure became an innovation: while LLMs cannot play strategically, their patterns of confusion are remarkably consistent. When an LLM systematically avoids a mechanism, that mechanism’s description is probably ambiguous. We had accidentally built a rule clarity analyzer, something no existing game design toolkit offers.
The Winning Hybrid
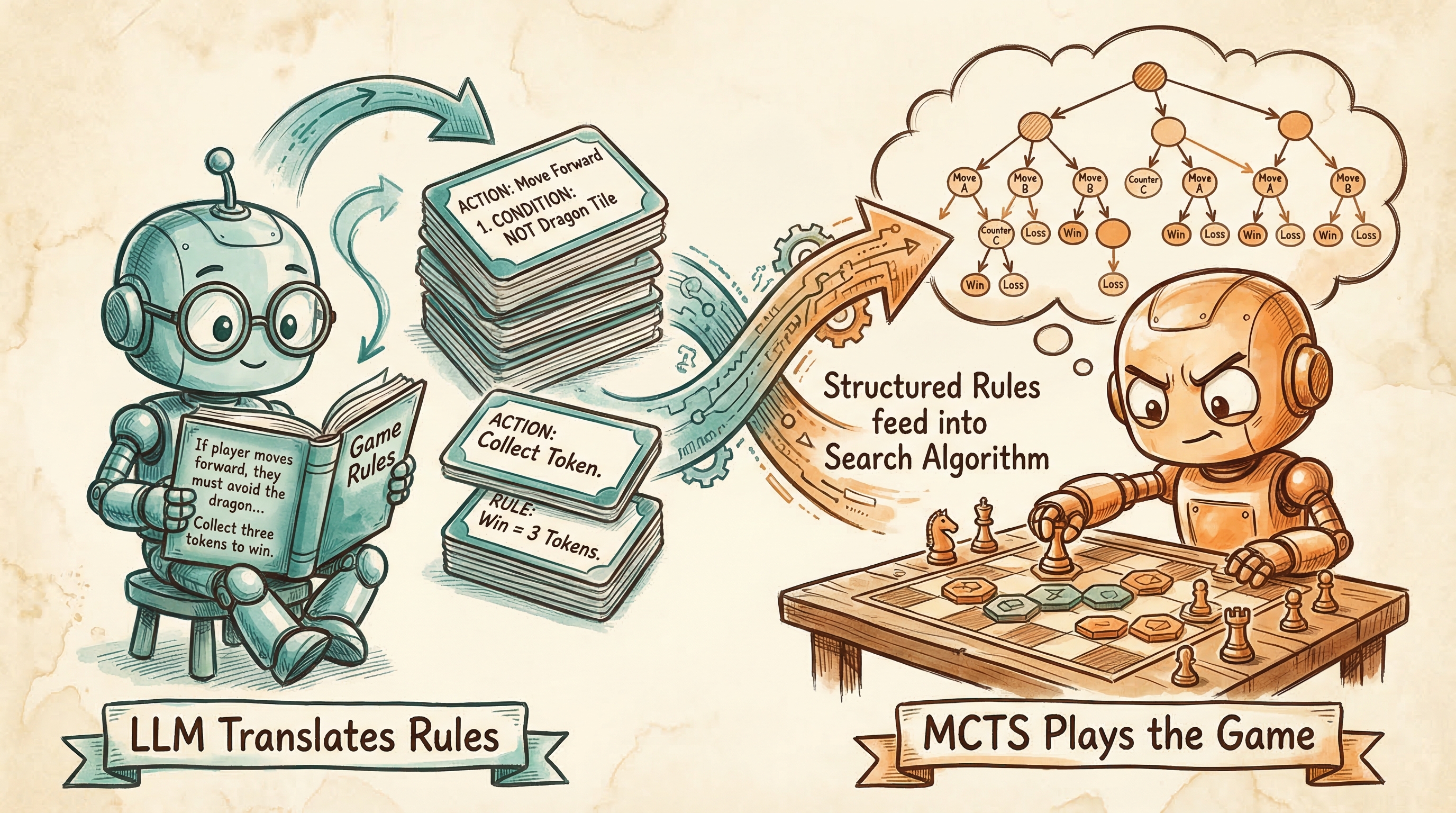
Figure. The winning approach: use the LLM for what it excels at (translating natural language into formal rules) and use traditional game AI for what it excels at (finding optimal play through search).
The production system uses each AI for its natural strength. The LLM reads your game’s mechanism descriptions and translates them into formal game actions, achieving roughly 90% coverage of Love Letter’s mechanics [5]. A deterministic engine then executes those actions with perfect rule enforcement.
For strategic play, we use MCTS (Monte Carlo Tree Search), a well-established game AI technique [6] that handles hidden information by sampling what opponents might hold and searching for the best move across those possibilities. On Love Letter, MCTS wins 81% of games against random play, a +62.4% skill gap that holds consistently across repeated runs. It runs entirely on local computation with zero API calls, so a designer can re-run the analysis after every single change.
The key insight is that each agent type serves a different purpose:
| Agent Type | Skill Gap | What It Measures |
|---|---|---|
| MCTS | +62.4% | Whether your game rewards strategic play |
| LLM | -39% | Which rules are confusing (clarity signal) |
| Random | 0% (baseline) | Balance and statistical fairness |
A negative skill gap means the LLM loses to random play more often than it wins. In other words, attempting to reason about the game actively hurts performance. The LLM does not fail because it is unintelligent. It fails because it cannot hold consistent game state across turns: it forgets what cards have been played, misapplies rules it understood one turn ago, and second-guesses valid strategies. A random agent, which needs no memory at all, outperforms it simply by avoiding these compounding errors.
MCTS proves whether the game rewards skill. LLMs reveal which rules are confusing. Each agent type is useless at the other’s job.
What the System Detects
The playtesting pipeline produces four categories of analysis. The first three run entirely on local computation after an initial LLM parse (which is cached per design version). The fourth uses LLM agents for rule clarity scoring.
Balance Metrics (Random Agents)
Six statistical metrics from 100+ random-agent self-play games:
| Metric | What It Catches |
|---|---|
| Seat advantage | First/last player wins too often |
| Strategy diversity | One action dominates all others |
| Dead actions | Game elements nobody uses |
| Game length | Too short, too long, or too variable |
| Elimination timing | Players knocked out too early |
| Stalemate rate | Games that never end |
Skill Gap (MCTS Agents)
MCTS agents play half the seats, random agents play the other half. The win rate difference measures whether the game rewards strategic play. Above +50% is strong strategic depth. Below +20% may feel random. Negative means strategic play is counterproductive, a sign that something is broken. Crucially, this analysis runs fast enough that a designer can tweak one number in the ontology and re-check within the same conversation.
Topology Balance (Spatial Games)
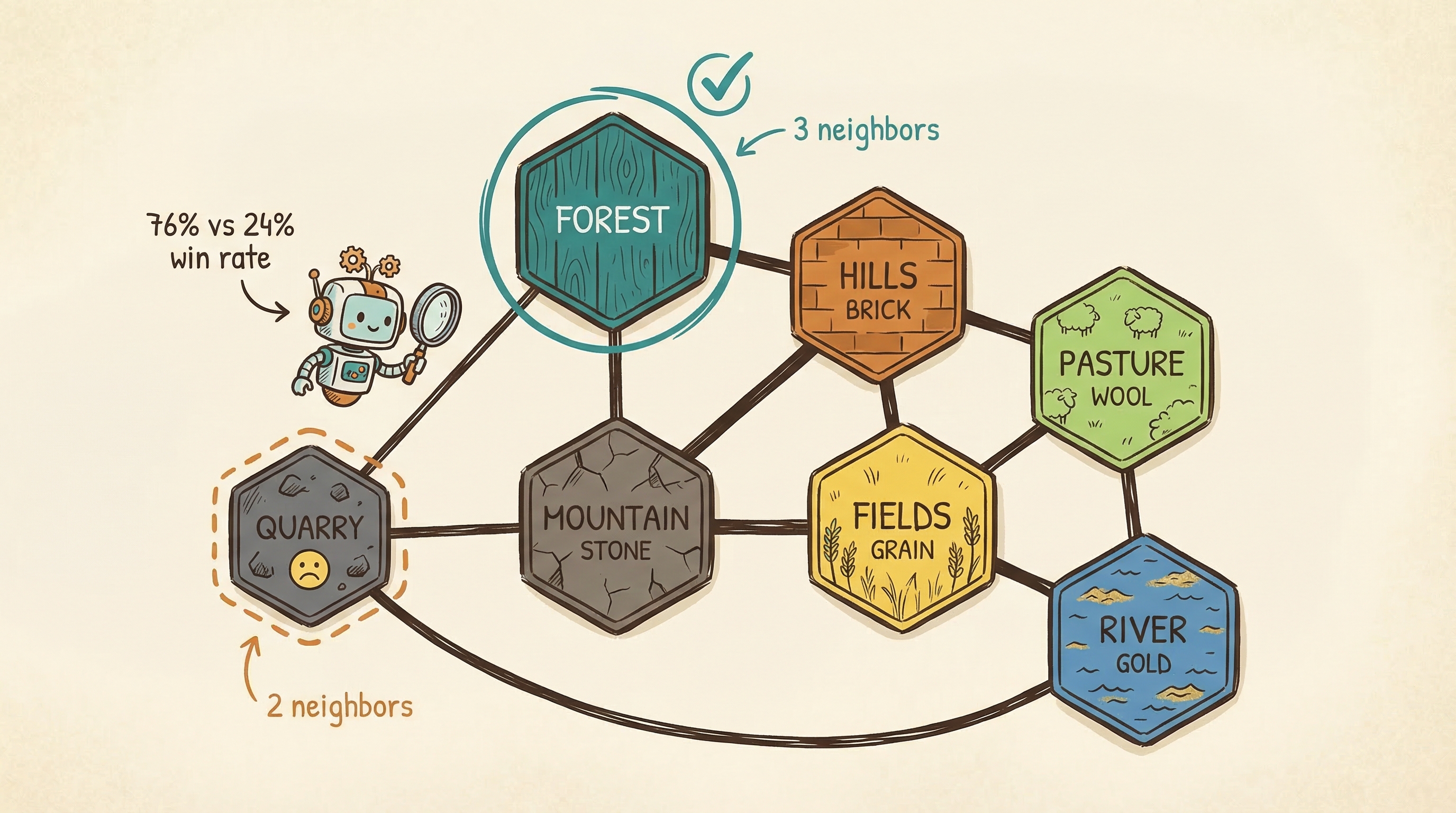
Figure. Three controlled experiments on Catan Simple decompose seat advantage into first-mover and topological components, revealing that board connectivity determines the outcome more than move order.
This is the finding we are most excited about. For games with structured board topology, the simulator detects balance properties that emerge from the shape of the board itself. We ran three experiments on a simplified Catan (7 hex regions, 2 players, first to control 4 regions wins):
Table II: Topology-Driven Balance (Catan Simple, 100 games each)
| Experiment | P0 Start (neighbors) | P1 Start (neighbors) | P0 Win% | P1 Win% |
|---|---|---|---|---|
| Baseline | Forest (3) | Quarry (2) | 76% | 24% |
| Swapped starts | Quarry (2) | Forest (3) | 45% | 55% |
| Symmetric starts | Forest (3) | Mountain (3) | 49% | 51% |
The key finding: the 76% advantage is topological, not temporal. When starting positions are swapped, the advantage reverses. When both players start on equal-connectivity regions, the game is nearly balanced (49/51). The board’s graph structure determines the outcome far more than move order.
This is something a human designer staring at a map would likely miss. You do not naturally count adjacency degrees when looking at a hex grid. The simulator does. And the design intervention is fundamentally different: instead of tweaking turn order or action costs, you fix the board’s connectivity.
Rule Clarity (LLM Agents)
LLM agents play the game using different archetypes (including a “newbie” that deliberately misreads rules), and their confusion patterns produce per-mechanism clarity scores:
Table III: Per-Mechanism Clarity (Love Letter)
| Mechanism | Score | Signal |
|---|---|---|
| Draw a card at start of turn | 10.0 | Mandatory, always clear |
| Priest: look at opponent’s hand | 9.9 | Clear, chosen often |
| Play a card | 9.6 | Low uncertainty |
| Guard: guess opponent’s card | 9.0 | Rarely chosen |
| Prince: force discard and redraw | 8.6 | Near-zero usage |
| Baron: compare hands | 8.5 | Never chosen across 135 opportunities |
The Baron’s comparison mechanic scores lowest every time. It requires reasoning about relative card values, which is the most complex rule in Love Letter. The LLM systematically avoids it. For a designer, this is specific, actionable feedback: the Baron’s rule needs the most clarification effort in your rulebook.
What Works Now: Game Tier Coverage
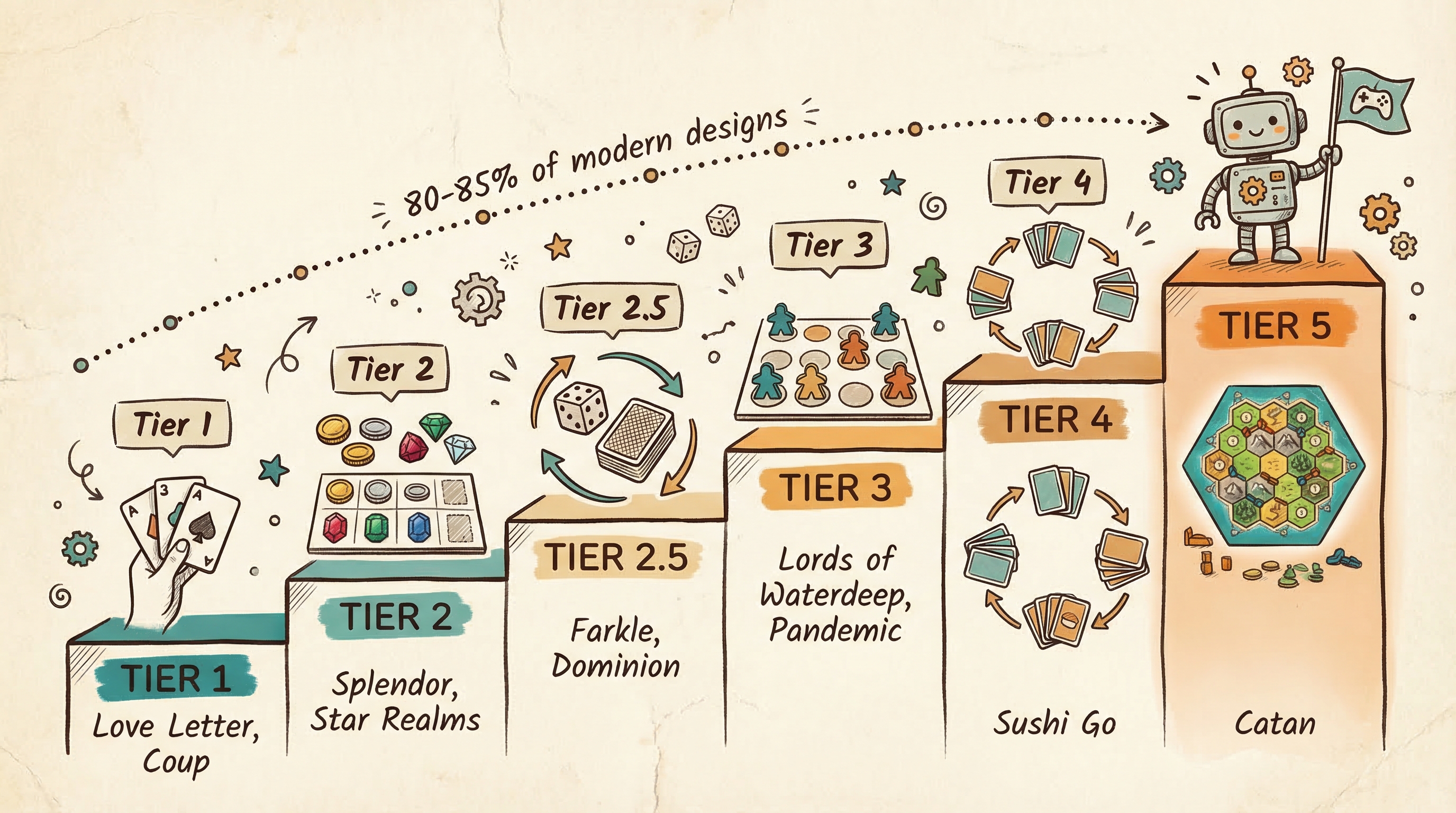
Figure. The simulator covers Tier 1 through Tier 5, roughly 80-85% of modern board game designs. Each tier adds new mechanism categories.
The simulator handles Tier 1 through Tier 5 games, covering roughly 80-85% of modern board game designs.
Table IV: Mechanism Tier Coverage
| Tier | Complexity | Examples | Key Mechanics |
|---|---|---|---|
| 1 | Light card games | Love Letter, Coup | Draw, play, compare, eliminate |
| 2 | Resource/market games | Splendor, Star Realms | Resource pools, markets, tableaux |
| 2.5 | Dice/deck building | Farkle, Dominion | Dice pools, push-your-luck, deck cycling |
| 3 | Worker placement, cooperative | Lords of Waterdeep, Pandemic | Action spaces, blocking, shared resources, team win/loss |
| 4 | Simultaneous action, card drafting | Sushi Go | Staged selection, draft passing, set collection scoring |
| 5 | Spatial, area control | Catan | Board graph, region ownership, parameterized actions |
What Does Not Work Yet
We believe in being honest about limitations. The following categories remain unsupported, and Nova’s coverage gate communicates this to designers before they try:
| Category | Examples | What Is Missing |
|---|---|---|
| Route building | Ticket to Ride | Pathfinding, longest-path scoring |
| Auction/bidding | Power Grid, For Sale | Bid state, auction resolution |
| Trick-taking | The Crew, Hearts | Trick structure, follow-suit, trump |
| Complex triggers | Wingspan, Terraforming Mars | Cascading effects, conditional activation |
| Asymmetric powers | Root, Vast | Per-player unique actions and win conditions |
These gaps represent genuine architectural breaks: complex triggers require an event system, asymmetric powers require per-player action sets, and route building requires pathfinding algorithms. Each is a future engineering epic, not a configuration change. The goal is not to simulate every game ever made. It is to cover the games that GameGrammar generates well enough that playtesting becomes a conversation, not a project.
Honest Challenges
No system is without limitations, and we think being transparent about ours strengthens rather than weakens the case for automated playtesting.
LLM parsing is non-deterministic. Two independent parses of the same game produce slightly different rule interpretations. The fix is pragmatic: parse once, cache the result, and reuse it for all subsequent simulations. Same cache plus same seed equals identical results. But designers should know that the initial parse defines the game the simulator plays, and it may not perfectly match their intent.
Evaluation uses simplified games. Our fixtures are simplified versions of published games: Love Letter with 8 card types, Catan with 7 regions, Dominion with a limited card pool. Full-complexity games (Terraforming Mars with 200+ project cards, Gloomhaven with asymmetric character decks) would stress the system in ways we have not yet tested.
Rule clarity has not been validated against humans. The Baron comparison mechanic consistently scores lowest, which makes intuitive sense because it is objectively the most complex rule in Love Letter. But we have not yet compared our automated clarity scores with actual human confusion ratings. The metric is plausible and useful, but formally unvalidated.
The simulator plays the game-as-parsed, not the game-as-intended. If the parser misinterprets a mechanism, the balance findings are real findings about the wrong game. The pattern parser’s artificial P3 advantage in Love Letter was exactly this kind of error. The LLM parser’s 90% accuracy is high, but the remaining 10% can produce subtle distortions.
These are known limitations, not hidden ones. Nova’s coverage gate and the simulator’s deterministic replay make them manageable in practice.
Concluding Remarks
When we started this research, the question was simple: can AI learn to play a board game by reading its structured design description? The answer turned out to be more nuanced than yes or no.
MCTS can play, and play well. +62.4% skill gap on Love Letter, pure local computation, zero API calls. Traditional game AI algorithms, when fed a structured game definition parsed from natural language, produce reliable strategic play. The game rewards skill, and MCTS finds the skill.
LLMs cannot play, and that is the point. -39% skill gap after 100 games. But the pattern of their confusion measures something no other tool measures: rule clarity. An LLM that systematically avoids a mechanism is telling you that mechanism is hard to understand. This inverts the standard framing where LLM game-playing failure is a deficiency to overcome. In our system, the failure is the feature.
Structure reveals what intuition misses. A 76% win rate from a 3-neighbor region versus a 2-neighbor region. No human designer spots that by staring at a map. The simulator does. And the design intervention (fix the board connectivity) is fundamentally different from what the designer would have tried (tweak the card costs).
The goal was never to replace human playtesters. Human playtesting reveals social dynamics, emotional arcs, and “feel” that no simulator captures. The goal was to compress the iteration cycle. Instead of weeks between design changes and feedback, the loop now fits inside a single conversation with Nova. Change a parameter, re-run the analysis, see the impact, iterate again. For Tier 1-5 games, that continuous feedback loop transforms playtesting from a project into a conversation.
If you would like to try automated playtesting on your own designs, GameGrammar is in public beta with a free tier that includes balance analysis via Nova. Already have a game? You do not need to generate from scratch — describe your existing design to Nova and run balance analysis on the game you built.
Series Navigation
- Unlocking the Secrets of Tabletop Games Ontology (Part 4)
- Introducing GameGrammar: AI-Powered Board Game Design (Part 5)
- GameGrammar: The Theory of Generative Board Game Design (Part 6)
- Nova: The AI Co-Designer That Learns Your Taste (Part 7)
- Generative Ontology: From Game Knowledge to Game Creation (Part 8)
- » AI Playtesting: When Your Game Tests Itself (Part 9)
References
[1] Geoffrey Engelstein and Isaac Shalev. Building Blocks of Tabletop Game Design: An Encyclopedia of Mechanisms. CRC Press, 2020.
- Comprehensive mechanism taxonomy and the iterative playtesting challenge
[2] D. Costarelli et al. GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents. arXiv:2406.06613, 2024.
- Documents systematic LLM failures including state-tracking loss and rule hallucination
[3] Z. Duan et al. GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations. NeurIPS 2024.
- Finds LLMs with Chain-of-Thought universally fail against MCTS
[4] Y. Hu et al. Large Language Models and Games: A Survey and Roadmap. arXiv:2402.18659, 2024.
- Comprehensive survey including the After-State Text Protocol pattern for LLM game interaction
[5] C. Becker et al. Boardwalk: Towards a Framework for Creating Board Games with LLMs. SBGames 2025.
- Board game code generation from LLMs, achieving 55.6% error-free rate
[6] R. Coulom. Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. CG 2006, LNCS 4630, Springer, 2007.
- Introduced UCT selection, the foundation of our MCTS agent
[7] E. Piette et al. Ludii: The Ludemic General Game System. arXiv:1905.05013, 2020.
- General game system requiring formal game descriptions (our system accepts natural language)
[8] Benny Cheung. Generative Ontology: When Structured Knowledge Learns to Create. arXiv:2602.05636, Feb 2026.
- Formal paper on the Generative Ontology framework with ablation study
[9] GameGrammar. Dynamind Research, 2026.
- Board game design platform with integrated automated playtesting



