artwork by DALL.E 3
Cracking the Spell of Q* - A New Method in Problem Solving
Philosophy of AI
Part 1 of 6In the dynamic and ever-changing landscape of AI and computational problem-solving, there arises a new speculative yet intriguing proposal: Q* (pronounced “Q-star”) - This conceptual framework is imagined to position itself at the intersection of three diverse yet interrelated technologies: the A* algorithm, Q-learning, and Large Language Models (LLMs) as systems of compressed knowledge. Although still theoretical, this amalgamation of Q* suggests a synergy that could potentially push the boundaries of AI’s problem solving efficiency and effectiveness, offering a novel approach to tackling complex challenges.
[2024/10/04] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/q-star-new-method-in-problem-solving/Podcast_Spell_of_QStar.mp3
Disclaimer: While it’s probable that our interpretation of the Q* concept doesn’t align with the mysterious breakthrough by OpenAI mentioned in recent Reuters’s news article, this investigative article has served a great inspiration to solve our AI problems.
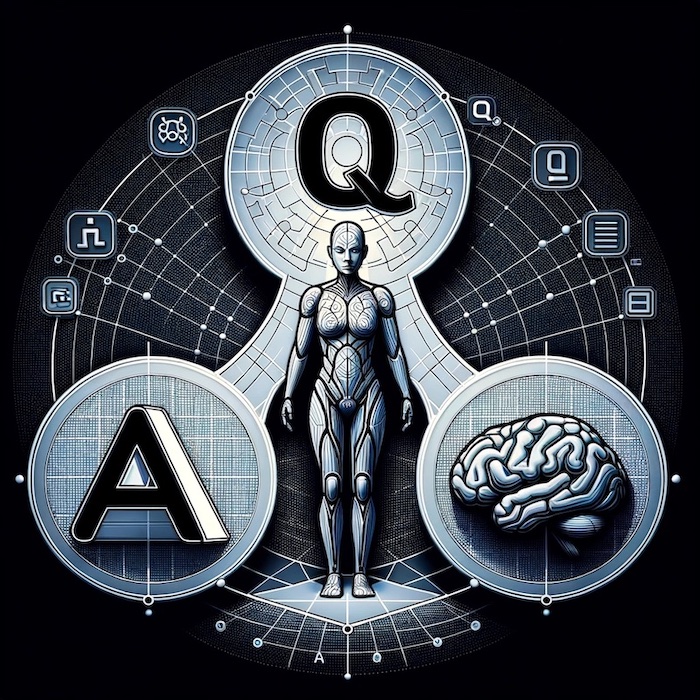
Figure. An abstract representation of the concept Q* incorporating the elements of A* search, LLM memory, and Q-learning method in reinforcement learning
The A* algorithm, renowned for its search capabilities, has long been the go-to method in navigating through complex spaces, whether in gaming environments or robotic path planning. Its heuristic-based approach enables it to make informed guesses about the most efficient paths, dramatically reducing the time and computational resources required to reach a destination. However, the static nature of A* limits its ability to adapt to dynamic environments or learn from past experiences.
Enter Q-learning, a form of reinforcement learning that excels in environments where adaptability and experience-based decision-making are key. Q-learning allows an agent to learn from the consequences of its actions, adapting its strategy to maximize cumulative rewards. This learning capability makes it an ideal partner for A*, bringing a dynamic, adaptive edge to the algorithm’s robust search mechanism.
The third pillar of Q*, LLMs as compressed knowledge systems, introduces a new dimension to this equation. These models, epitomized by systems like GPT-4, represent a paradigm shift in handling and processing vast amounts of information. By compressing global knowledge into a probabilistic model, LLMs offer a unique form of memory system that Q* can exploit. This integration allows Q* to not only navigate and learn from its environment but also to tap into a wealth of knowledge that can inform and enhance its decision-making processes.
The potential impact of Q* in advanced computational problem-solving is immense. From navigating complex data landscapes to solving intricate real-world problems, Q* stands poised to redefine the boundaries of what is possible in AI. Its ability to combine efficient search, adaptive learning, and deep, compressed knowledge opens up new avenues for exploration (on search) and exploitation (on knowledge).
As we continue in this article, we will explore the individual components of Q*, how they synergistically interact, and the practical applications of this new approach. Join us on this journey into the heart of Q*, a beacon of the future of problem-solving in the age of intelligent agents.
Why denoted the method as Q*?
In the method of Q-learning, “Q” represents “quality,” denoting the effectiveness or value of a specific action within a particular state. Fundamentally, it serves as an indicator of the desirability or suitability of undertaking a given action in a certain context. Additionally, “Q*” carries a symbolic significance, representing the highest Q value achievable across all possible search policies, signifying the most optimal action to be taken. Alternatively, the “*” can come from A* algorithm which is providing the optimal search policy for the solution space.
Background Knowledge
The A* Algorithm
At the heart of Q* lies the A* algorithm, a well-known AI tool in the world of search and navigation. A* is a heuristic-based algorithm, which means it makes educated guesses to find the shortest path between two points. This approach distinguishes it from brute-force methods, enabling it to solve complex search problems efficiently.
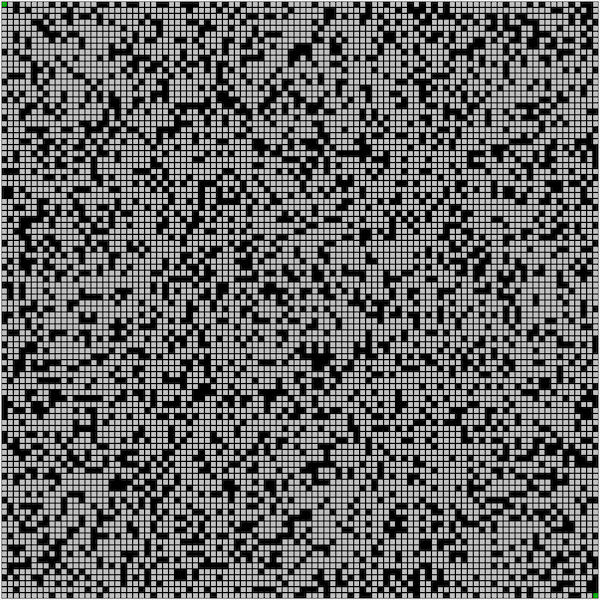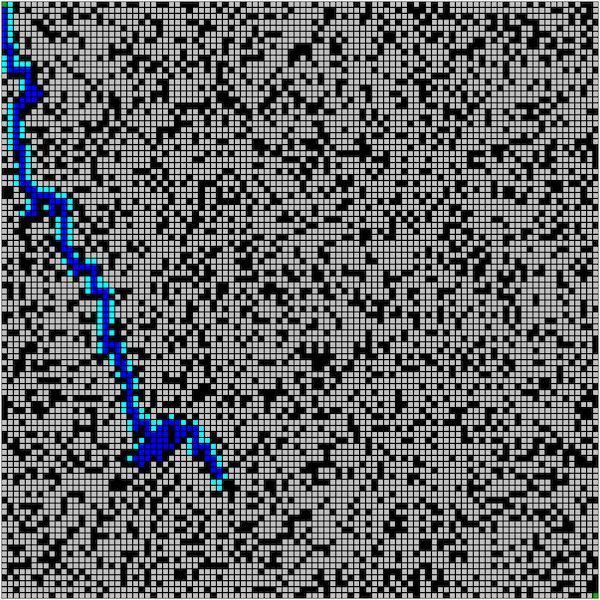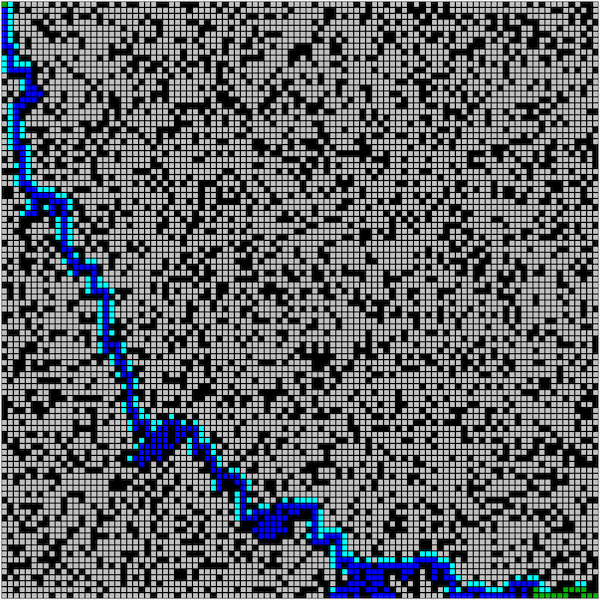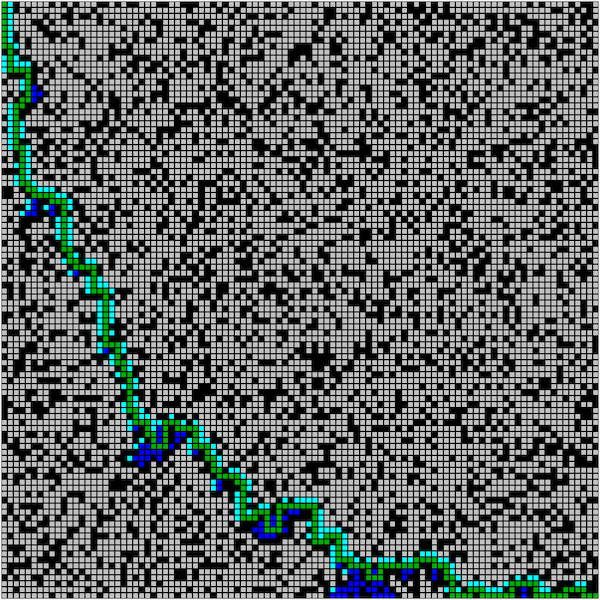
Figure. A* algorithm animation on optimal path finding (image credit: imgur comacomacomacomachameleon)
To understand A*, let start with the key features in the algorithm:
-
Heuristic Function: The core of A*’s efficiency lies in its heuristic function. This function estimates the cost to reach the goal from a given point, often using a measure like straight-line distance. This estimation helps A* to focus its search in the direction of the goal, significantly speeding up the process.
-
Cost Calculation: A* calculates two types of costs - the $g$ cost, which is the known cost from the starting point to the current point, and the $h$ cost, the estimated cost from the current point to the goal as provided by the heuristic. The total cost, $f$, is the sum of these ($f = g + h$). This calculation ensures that A* keeps track of both the ground covered and the journey ahead.
-
Path Prioritization: A* continuously keeps track of multiple paths and prioritizes them based on their $f$ cost. The path with the lowest $f$ cost is explored first (very similar to BFS or beam search), ensuring that the algorithm always follows the most promising path towards the goal.
Q-Learning Explained
Complementing the A* algorithm in Q* is Q-learning, a type of Reinforcement Learning (RL). Unlike traditional algorithms that follow predefined rules, Q-learning enables an agent to learn optimal actions through trial and error interactions with its environment.
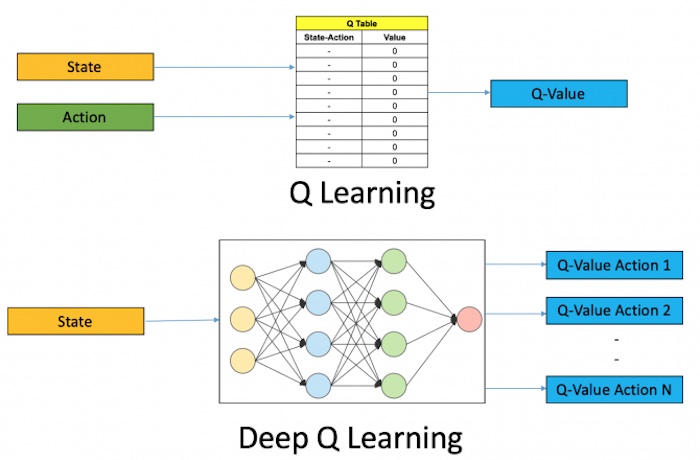
Figure. Q-Learning vs Deep Q-Learning. (image credit: Assembly AI, Reinforcement Learning With (Deep) Q-Learning Explained).
Adaptability and Experiential Learning:
-
Learning from the Environment: In Q-learning, an agent learns by taking actions and observing the outcomes. This process helps the agent to understand which actions yield the best results in different situations.
-
Adaptation: The key strength of Q-learning is its adaptability. It can adjust its strategies based on the feedback from its environment, making it highly effective in dynamic or unpredictable settings.
Instead of RL equations, we shall use the following practical steps to explain the Q-learning. Essentially, “Q”-value is a measure of how good it is to take a certain action when in a particular situation.
- The agent starts with a Q-table, which is like a cheat sheet that it fills out as it learns. The table helps the agent remember which actions lead to rewards and which lead to penalties.
- Initially, the agent doesn’t know anything, so the Q-table is full of zeros or random values. It starts exploring the maze, making random choices about where to go.
- Every time the agent makes a move, it gets feedback from the environment: rewards for good moves and penalties for bad ones.
- The agent updates the Q-table with this new information. It does this using a formula that takes into account the current reward, the maximum predicted future rewards, and the existing value in the Q-table. This update is aimed at improving the agent’s guess about how good it is to take a certain action when in a specific state.
- Over time, with enough exploration and learning, the Q-table gets filled with values that reflect the best actions to take in every state.
- Eventually, the agent relies more on the Q-table to make decisions rather than random choices. It begins to take the path with the highest rewards according to what it has learned.
The goal is for the robot to end up with a Q-table that tells it the best action to take in any situation to maximize its rewards, which means finding the fastest way through the maze without hitting walls.
LLMs as Compressed Knowledge Systems
The third component of Q* is the use of Large Language Models (LLMs). LLMs, such as GPT-4, represent a breakthrough in how machines can handle vast amounts of information.
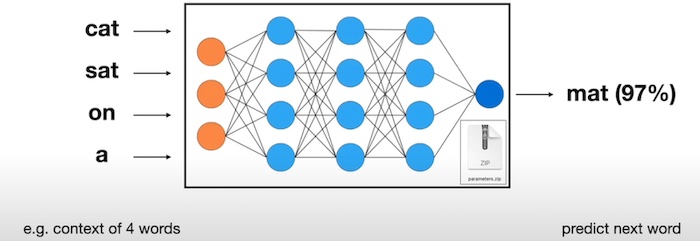
Figure. This diagram explained how the LLM neural network works intuitively by drawing the compressed knowledge from pretraining. In this example, by giving the context of 4 words “cat sat on a”, the model predicts the next word is “mat” with 97% confidence. (image credit: Andrej Karpathy, Intro to Large Language Models, video, 22 Nov 2023).
Compressed Knowledge and Probabilistic Predictions:
-
Encoding Vast Information: LLMs compress a wide range of information, patterns, and relationships found in massive text corpora. This compression is a form of lossy information storage, where the model captures the essence of the data rather than exact details.
-
Probability-Based Predictions: LLMs use probabilistic models to make predictions. When generating text, for instance, an LLM predicts the next word based on the likelihood of its occurrence in the given context. This approach allows LLMs to generate coherent and contextually appropriate responses despite the lossy nature of their knowledge compression.
This foundational understanding of A*, Q-learning, and LLMs as knowledge systems sets the stage for exploring their synergistic integration in Q*.
The Fusion of A*, Q-Learning, and LLMs
The integration of A*, Q-learning, and Large Language Models (LLMs) in the Q* approach marks a significant leap in computational problem-solving. This section explains how these three components work in harmony, creating a system that is greater than the sum of its parts.
Synergistic Contribution to Q*
-
A* for Efficient Search: A* brings to Q* its unparalleled efficiency in navigating through complex paths. Its heuristic approach quickly identifies the most promising paths, significantly reducing computational overhead.
-
Q-Learning for Dynamic Adaptation: Q-learning adds a layer of adaptability and learning from experience. As conditions change or new information becomes available, Q-learning enables Q* to adjust its strategies, optimizing for better outcomes over time.
-
LLMs as a Knowledge Repository: LLMs serve as a vast reservoir of knowledge. They provide Q* with a broad understanding of the world, offering context and insights that are not explicitly encoded in the algorithm’s immediate environment.
Enhancing Problem-Solving Efficiency: Hypothetical Examples
Imagine a self-driving car navigating a busy city using Q*. A* guides the car through the streets, efficiently calculating routes. However, the city is dynamic - roads close, traffic patterns change. This is where Q-learning steps in, enabling the car to learn from these changes and adapt its route planning. Simultaneously, LLMs assist in understanding complex traffic regulations or interpreting unexpected road signs, offering a depth of knowledge that goes beyond the immediate sensory input.
In another scenario, consider a healthcare AI using Q* for medical diagnosis. A* could quickly sift through symptoms to form preliminary diagnoses, while Q-learning would adapt these diagnoses based on patient outcomes and emerging medical research. LLMs would provide a comprehensive medical knowledge base, ensuring that the AI’s suggestions are grounded in the latest medical literature.
LLMs: A Memory System for Q*
The role of LLMs in Q* is akin to a sophisticated memory system. Unlike traditional memory storage that retains static information, LLMs offer dynamic and contextually rich knowledge. This attribute of LLMs allows Q* to go beyond mere data retrieval; it can generate insights, predict outcomes, and even propose creative solutions. In essence, LLMs give Q* the ability to understand and interact with information in a nuanced and human-like manner, greatly expanding its problem-solving capabilities.
Next, we shall look at how to integrate Q* into the Tree of Thoughts planning framework.
Q* within the Tree of Thoughts (ToT) Framework
Entering the Tree of Thoughts
The Tree of Thoughts (ToT) framework represents a significant advancement in the use of Large Language Models (LLMs) for complex problem-solving. At its core, ToT is a structured approach that enables language models to generate, evaluate, and iterate over a series of “thoughts” or ideas, each leading towards a potential solution to a given problem. This process is akin to building a tree, where each branch represents a different line of reasoning or a pathway of exploration.
Interestingly, the Tree of Thoughts: Deliberate Problem Solving with Large Language Models paper’s “Related Work” section has mentioned that ToT is a modern rendition of A* algorithm, in which the heuristic at each search node is provided by the LLM’s self-assessment.
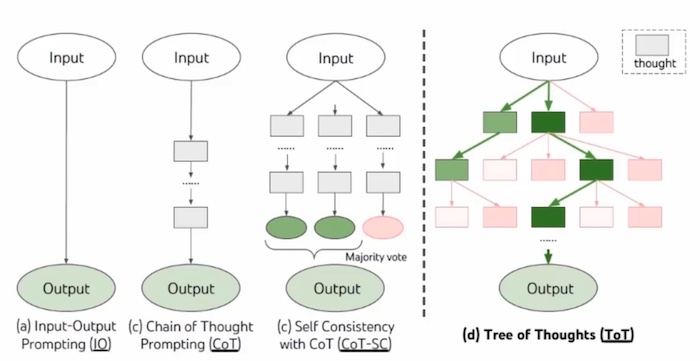
Figure. Schematic illustrating various approaches to problem solving with LLMs. Each rectangle box represents a thought, which is a coherent language sequence that serves as an intermediate step toward problem solving. (image credit: Yao, L., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models, 2023)
Key Aspects of ToT:
-
Structured Problem-Solving: ToT structures the problem-solving process into a tree-like framework, where each node represents a distinct thought or idea.
-
Search Algorithms: To navigate this tree, search algorithms like Depth-First Search (DFS), Breadth-First Search (BFS), and beam search are employed. These algorithms help in systematically exploring different pathways, allowing the model to consider various possibilities before arriving at a solution.
-
Role of LLMs: LLMs, with their vast repository of knowledge, play a crucial role in generating the content of each thought. They provide the necessary context and information that guide the exploration and evaluation process within the ToT framework.
Integrating Q* into ToT
The integration of Q* into the ToT framework opens up exciting new possibilities for enhanced decision-making and problem-solving capabilities.
Conceptualizing Q* within ToT:
-
Augmenting Search with A* and Q-Learning: The A* component of Q* can be utilized to efficiently navigate the ToT, identifying the most promising thoughts or branches to explore. Meanwhile, Q-learning allows the system to learn from previous explorations within the tree, adapting its strategy over time based on the outcomes of different paths.
-
Dynamic Adaptation and Learning: As conditions change or new information is encountered, Q* enables ToT to dynamically adjust its approach, ensuring that the exploration remains relevant and effective.
The Contribution of LLMs in ToT:
-
Enhanced Knowledge Base: LLMs contribute a deep and nuanced understanding of the problem context, enriching the thoughts generated within the ToT. This can lead to more informed decision-making and a broader exploration of potential solutions.
-
Contextual Relevance and Creativity: With LLMs, the ToT is not just navigating a static set of ideas. Instead, it’s capable of generating novel thoughts and solutions, tailored to the specific nuances of the problem at hand.
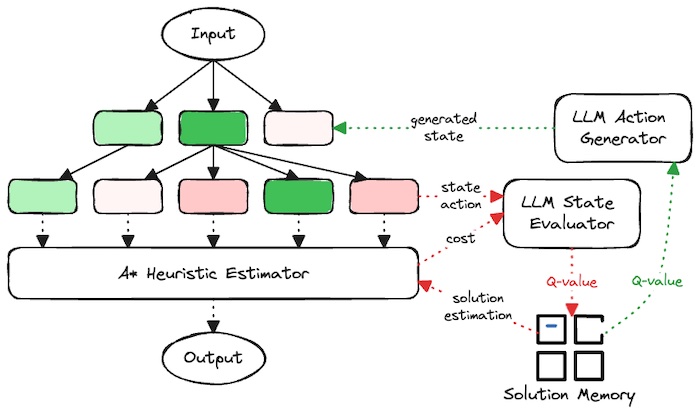
Figure. The diagram encapsulates the abstract system of the Q* method applied within the Tree of Thoughts (ToT) framework, illustrating a sophisticated approach to problem-solving.
From the diagram, the system receives an input and generates a ToT. The A* Heuristic Estimator guides the exploration through this tree, while the LLM components enrich this process with deep, context-sensitive knowledge. The Q-learning aspect dynamically learns from each iteration, enhancing the system’s ability to adapt and improve its strategy over time. The output is the solution or decision deemed most effective based on this integrated process.
- Input: This is where the problem or scenario is introduced into the system.
- ToT Structure: Represented by the interconnected nodes (green and red), this structure reflects the tree of possible thoughts or actions generated by the system.
- A* Heuristic Estimator: This component, connected to each node in the ToT, evaluates the most promising pathways to follow. It uses heuristics to estimate the ‘cost’ of each action, prioritizing those with the highest potential to lead to a solution.
- LLM Action Generator: Once the A* Heuristic Estimator identifies a potential thought or action, the LLM Action Generator is responsible for creating new states or actions based on the deep knowledge contained within the LLMs.
- LLM State Evaluator: This evaluates the generated states or actions, considering the context and the broader knowledge base of the LLMs. It assesses whether the new state or action brings the system closer to a solution.
- Q-learning: Illustrated by the dotted lines leading to the “Q-value” boxes, this reflects the learning aspect of Q*. It evaluates the effectiveness of each action (state-action cost) and updates the strategy based on the feedback (solution estimation), learning from past actions and adjusting future actions to optimize decision-making.
- Solution Memory: This is where the Q-values are stored, essentially the memory of the system, which holds the learned values of action quality, informing future decisions.
By integrating the efficiency of A* in search the ToT, the dynamic learning capabilities of Q-learning, and the expansive knowledge of LLMs, the Q* method within ToT presents a formidable approach to addressing complex, adaptive challenges in various domains. It combines the structured exploration of ToT with the adaptive, knowledge-rich capabilities for tackling complex and dynamic challenges. This integration not only enhances the efficiency and effectiveness of the ToT framework but also vastly expands its potential applications in various domains.
Practical Applications
The Q* framework, while offering a promising suite of capabilities through the convergence of A*, Q-learning, and LLMs, also brings with it considerable complexity. It’s important to recognize that not all problems require such an intricate solution—sometimes a simpler tool will suffice. However, for significant and intricate challenges that lack satisfactory existing solutions, the Q* framework could be a formidable asset. This section will explore some potential practical applications of the Q* framework.

Figure. The illustration showcases the application of Q* in environmental management and climate modelling, featuring a futuristic control center with advanced data processing systems, climate models, and environmental data visualizations.
Examples of Q* Application
-
Urban Planning and Smart Cities: Q* has the potential to transform urban planning by enhancing traffic flow, public transport logistics, and emergency response protocols. Leveraging its ability to analyze and predict traffic patterns, Q* could suggest dynamic rerouting strategies that respond to real-time conditions like ongoing events, weather changes, and the unique pulse of city life.
-
Healthcare Diagnostics and Treatment Planning: The healthcare sector could see a paradigm shift with Q*’s capacity to personalize diagnostics and treatment plans. Integrating individual health records with cutting-edge medical research, Q* might offer bespoke treatment options, foresee complications, and seamlessly adjust health recommendations as fresh data emerges.
-
Environmental Management: In environmental science, Q* could assist in climate modelling and ecosystem management. Its ability to process vast data sets and adapt to new information could be pivotal in predicting climate change effects and suggesting mitigation strategies.
The deployment of Q* is poised to create ripples across various industries, enhancing the way we tackle and solve complex issues. Despite the hurdles and constraints that may arise, the continuous evolution of the Q* framework could signal a new chapter in AI development, redefining our approaches to complex problem-solving.
Final Remark
As we have explored throughout this article, Q*, with its innovative amalgamation of the A* algorithm, Q-learning, and Large Language Models (LLMs), represents a significant leap forward in the field of computational problem-solving. This framework has the potential to redefine the boundaries of what artificial intelligence can achieve, offering new solutions to complex, dynamic challenges across various domains.
The integration of efficient search, adaptive learning, and a vast repository of knowledge allows Q* to tackle problems with a level of sophistication and effectiveness previously unattainable. From urban planning to healthcare, from environmental management to the methods of scientific research, the applications of Q* are expected as diverse as they are impactful.
In closing, Q* stands not just as a speculative step forward towards on top of the recent AI achievements but also as a beacon of what is possible in the future. It invites us to imagine a world where complex problems are met with equally sophisticated solutions, where AI not only supports but enhances human decision-making, and where the boundaries of what we can solve expand beyond what we currently perceive. Subsequently, we will proceed with a more technically assessment of the Q* method. If our speculative understanding prove accurate, we intend to design and implement the system as the next progression.
Resources
For those interested in studying deeper into the concepts and technologies discussed in this article, the following resources provide valuable information and insights into Q*, A*, Q-learning, LLMs, and the Tree of Thoughts framework:
- A* Algorithm:
- Amit Patel, Amit’s A* Pages, Red Blob Games
- An extensive guide on the A* algorithm, offering a comprehensive look at how it works and its applications.
- Amit Patel, Red Blob Games: A* Pathfinding, Red Blob Games
- An interactive tutorial on A* pathfinding, ideal for those who prefer a hands-on approach to learning.
- Amit Patel, Amit’s A* Pages, Red Blob Games
- Q-Learning:
- Sutton, Richard S., and Andrew G. Barto. Reinforcement Learning: An Introduction. Vol. 1. MIT Press, 2018.
- A foundational text offering an in-depth exploration of reinforcement learning, with a focus on Q-learning.
- Patrick Loeber, Reinforcement Learning With (Deep) Q-Learning Explained, AssemblyAI, 2 Feb 2022.
- In this tutorial, we learn about Reinforcement Learning and (Deep) Q-Learning.Q
- DeepLizard: Q-Learning Series
- A video series explaining the fundamentals of Q-learning in an accessible format.
- Sutton, Richard S., and Andrew G. Barto. Reinforcement Learning: An Introduction. Vol. 1. MIT Press, 2018.
- Large Language Models (LLMs):
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I., Attention is all you need, In Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017.
- The seminal paper introducing the Transformer model, which forms the basis for many modern LLMs.
- Andrej Karpathy, Intro to Large Language Models, video, 22 Nov 2023.
- This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What they are, where they are headed, comparisons and analogies to present-day operating systems, and some of the security-related challenges of this new computing paradigm.
- OpenAI’s Research Blog on Language Models
- A collection of articles and research papers from OpenAI, discussing various aspects of LLMs including GPT-4.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I., Attention is all you need, In Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017.
- Tree of Thoughts (ToT) Framework:
- Yao, L., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models, arXiv:2305.10601 (2023)
- A research paper introducing the concept of ToT in the context of decision-making AI.
- Long, J., Large Language Model Guided Tree-of-Thought, arXiv:2305.08291 (2023)
- A detailed exploration of the ToT framework in reinforcement learning.
- Yao, L., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models, arXiv:2305.10601 (2023)
- General AI and Machine Learning Resources:
- MIT OpenCourseWare: Introduction to AI
- A course by MIT, offering a broad overview of AI principles and techniques.
- Coursera: Machine Learning by Andrew Ng
- A popular online course that covers various aspects of machine learning, including algorithms like A* and reinforcement learning concepts.
- MIT OpenCourseWare: Introduction to AI
- Related Post
-
Benny Cheung, Game Architecture for Card Game AI (Part 3), Benny’s Mind Hack, 3 Jul 2021.
-
Benny Cheung, Adventures in Deep Reinforcement Learning using StarCraft II, Benny’s Mind Hack, 15 Nov 2019.
-
These resources provide a starting point for anyone looking to expand their understanding of these complex and fascinating topics. Whether you’re a student, a professional, or just an AI enthusiast, these materials offer valuable insights into the world of advanced computational problem-solving.





