artwork by Stable Diffusion AI
Ask a Book Questions with LangChain and OpenAI
Reading a book can be a fulfilling experience, transporting you to new worlds, introducing you to new characters, and exposing you to new concepts and ideas. However, once you’ve finished reading, you might find yourself with a lot of questions that you’d like to discuss. Perhaps you don’t have anyone nearby who has read the book or is interested in discussing it, or maybe you simply want to explore the book on your own terms. In this situation, you might be left wondering how long it will take to fully digest the book and answer your own questions. Without a tutor or friends around to provide guidance and discussion, you may need to take a more thoughtful and introspective approach to your reading.
Mortimer Adler famously advised in his classic book “How to Read a Book”,
“Reading a book should be a conversation between you and the author.”

Figure. Imagine that we are having a non-judgemental AI tutor to assist in the question and answer to a book. (credit: artwork by Stable Diffusion)
Imagine that we are having a non-judgmental AI tutor to assist in the question and answer process can be incredibly helpful, especially when it comes to exploring and applying the ideas presented in a book. An AI can provide unbiased and objective insights into the book’s themes and concepts, and help you to understand the author’s perspective on the subject matter. With an AI’s assistance, you can ask deeper and more meaningful questions, and receive thoughtful and informative responses that can help you to connect the ideas in the book to your own experiences and beliefs. This can lead to a more enriching before and after the reading experience.
[2024/10/05] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/ask-a-book-questions-with-langchain-openai/Podcast_Ask_a_Book_Questions.mp3
How to Build a AI Question and Answering System?
In this article, we take the practical approach of building a question and answering system. In the process, we explain how to perform semantic search and query on a book using OpenAI, LangChain, and Pinecone - an external vector store. The book is broken down into smaller documents, and OpenAI embeddings are used to convert them into vectors, which are then stored externally using Pinecone.
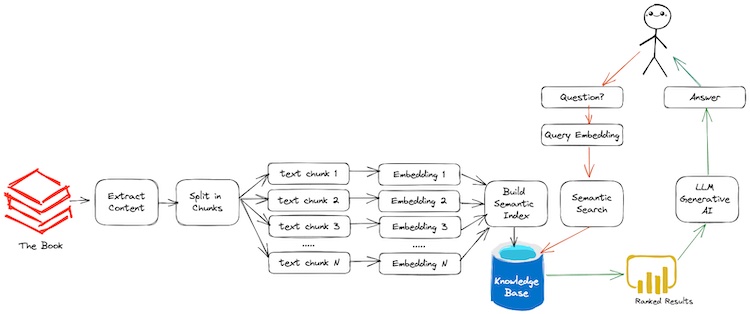
Figure. In this article, we shall walkthrough the process of (1) Extract the Book Content, (2) Split Book into Smaller Chunks, (3) Build Semantic Index and (4) Ask a Book Questions (the red arrows show the questioning flow and the green arrows show the answering flow).
Selected the Book
We are using an interesting and free online book: 60 Leaders on Artificial Intelligence, to illustrate the whole process. This is a book in PDF format and contains 236 pages including plenty of graphics. If we can automatically extract the unstructed text and build an index, subsequently to query and summarize from the content.

Figure. Using “60 Learders on Artificial Intelligence” for the implementation.
The example demonstrates how to ask a question in natural language and receive an answer using this technique. This approach is not limited to books and can be used for internal documents or external data sets as well. By following the steps outlined, readers will be able to conduct sophisticated searches on large volumes of text, which can assist in answering the questions that we might have after reading the book.
Installation
Using our philosophy of learning by doing, we shall take the practical approach to demonstrate how to install all the required Python modules to build a system. The latest LangChain, which has all the goodies of handling many unstructured document formats including PDF and Microsoft Words, requires Python >= 3.8.1. First, we are going to create a virtualenv nlp with python==3.9.
conda create -n nlp python==3.9
conda activate nlp
After we activate the nlp virtualenv, we can install LangChain with “all” modules needed for all integrations, run:
pip install -U langchain[all]
We want to add the OpenAI and Pinecone supports,
pip install openai
pip install pinecone-client
Running on Mac Platform Requirements
We are using a Mac M1 Pro to run the experiment. There are additional brew packages are required. (obviously, we cannot provide instruction on how to install on Windows).
- poppler is a free software utility library for rendering Portable Document Format (PDF) documents.
- tesseract is an optical character recognition (OCR) tool for python. That is, it will recognize and “read” the text embedded in images.
# Install other dependencies
# https://github.com/Unstructured-IO/unstructured/blob/main/docs/source/installing.rst
brew install libmagic
brew install poppler
brew install tesseract
# If parsing xml / html documents:
brew install libxml2
brew install libxslt
Unstructured File Loader
The LangChain Unstructured covers how to load files of many types. Unstructured currently supports loading of text files, powerpoints, html, pdfs, images, and more.
Other dependencies to install https://langchain.readthedocs.io/en/latest/modules/document_loaders/examples/unstructured_file.html
- unstructured make it easy to prepare unstructured data like PDFs, HTML and Word Documents for downstream data science tasks.
- layoutparser aims to provide a wide range of tools that aims to streamline Document Image Analysis (DIA) tasks.
- detectron2 is Facebook AI Research’s next generation library that provides state-of-the-art detection and segmentation algorithms.
pip install "unstructured[local-inference]"
pip install "detectron2@git+https://github.com/facebookresearch/detectron2.git@v0.6#egg=detectron2"
pip install layoutparser[layoutmodels,tesseract]
If you have the will to install all the requirements, you are ready to take on the actual implementation process.
Experimental Implementation
Let’s assume that the readers of this article have foundational knowledge of Python programming language and a basic understanding of Natural Language Processing (NLP). This will help them follow along with the technical aspects of the article and understand the concepts and techniques used in the implementation of the question answering system. However, we will strive to explain the key concepts in a clear and concise manner to ensure that readers of all backgrounds can benefit from this article.
Special thanks to Data Independent video and notebook inspired this implementation, see the References section.
1. Extract the Book Content
This code provides a basic example of how to use the LangChain library to extract text data from a PDF file, and displays some basic information about the contents of that file.
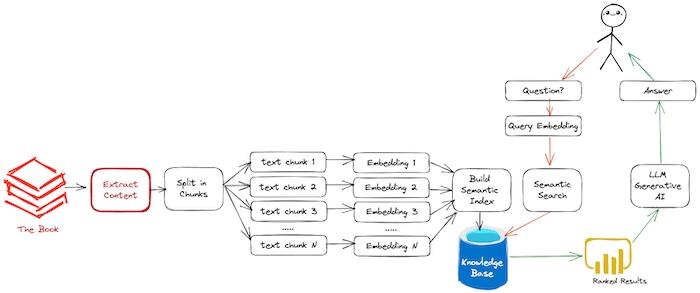
Figure. Showing Step (1) Extract the Book Content (highlight in red).
The document_loaders and text_splitter modules from the LangChain library. These libraries contain functions and classes that allow the user to access and manipulate text data from different sources. Specifically the UnstructuredPDFLoader, which is used to load and extract text from a PDF file. The path to the PDF file is specified as “data/60 Leaders on AI.pdf”.
from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = UnstructuredPDFLoader("data/60 Leaders on AI.pdf")
data = loader.load()
print (f'You have {len(data)} document(s) in your data')
print (f'There are {len(data[0].page_content)} characters in your document')
After loading the PDF file, it displays the number of characters in the first document’s page content.
You have 1 document(s) in your data
There are 533071 characters in your document
2. Split Book into Smaller Chunks
We will be dividing the loaded PDF document into smaller “pages” of 1000 characters each. The reason for doing this is to provide contextual information to OpenAI when we ask it a question. This is because OpenAI embeddings work best with shorter pieces of text. Instead of making OpenAI read the entire book every time we ask a question, it is more efficient and cost-effective to give it a smaller section of relevant information to process.
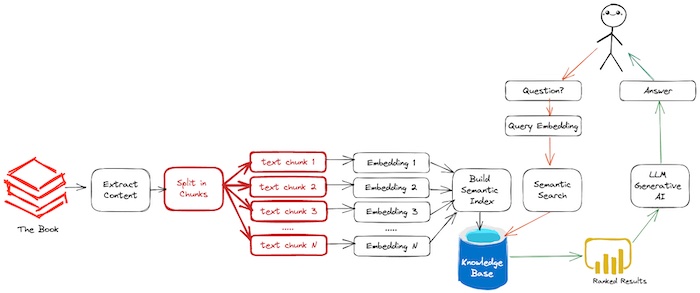
Figure. Showing Step (2) Split Book into Smaller Chunks (highlight in red).
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(data)
print (f'Now you have {len(texts)} documents')
Now you have 701 documents
Now, we have completed preparing the text and ready to take the next step.
3. Build Semantic Index
Create embeddings of our documents to get ready for semantic search. We store these vectors online in a Pinecone vector store so we can add more books to our corpus and not have to re-read the PDFs each time. We also assign a book namespace in the index.
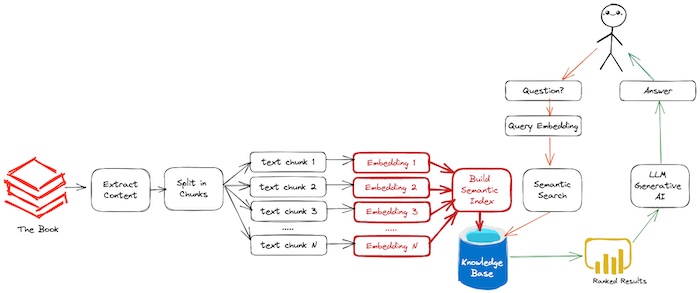
Figure. Showing Step (3) Build Semantic Index (highlight in red).
from langchain.vectorstores import Chroma, Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# initialize pinecone
pinecone.init(
api_key=PINECONE_API_KEY, # find at app.pinecone.io
environment=PINECONE_API_ENV # next to api key in console
)
index_name = "langchain-openai"
namespace = "book"
docsearch = Pinecone.from_texts(
[t.page_content for t in texts], embeddings,
index_name=index_name, namespace=namespace)
Once we’ve authenticated with both Pinecone and OpenAI API, we can use the from_texts() function to convert each document into a vector.
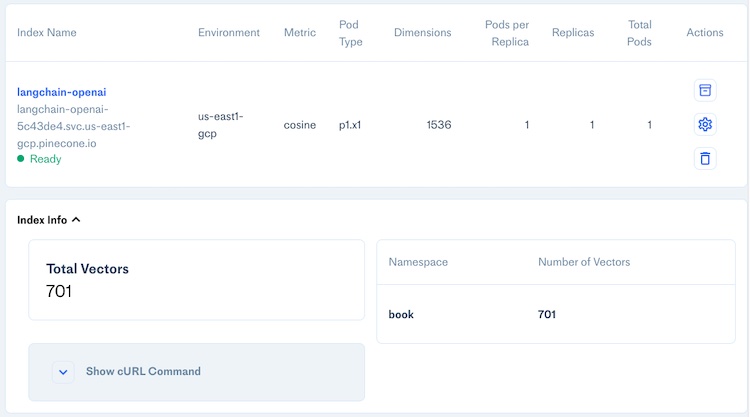
Figure. Showing the built Pinecone index with the index stats of 701 text vectors.
At this point, we have broken down the book into smaller documents, converted each document into a vector using OpenAI embeddings, and stored these vectors externally using Pinecone. We can move on to the next step, which is to build the actual question answering component!
4. Ask a Book Questions
After we built the index, we are ready to query those docs to get our answer back.
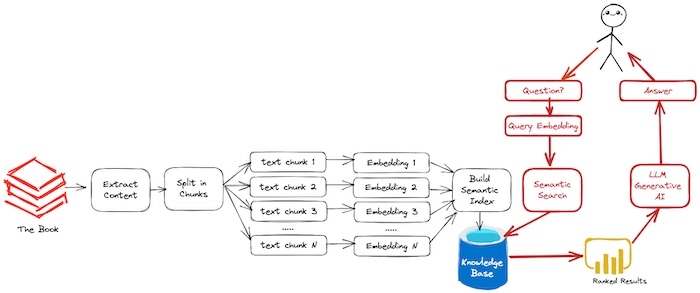
Figure. Showing Step (4) Ask a Book Questions (highlight in red).
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
llm = OpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "How to explain AI to a 5 years old?"
docs = docsearch.similarity_search(query,
include_metadata=True, namespace=namespace)
chain.run(input_documents=docs, question=query)
We shall ask our question,
How to explain AI to a 5 years old?
The QA chain will take the ranked result documents, and pass it to OpenAI to summarize exactly from the book content only! Finally, we can get the answer that is easy to comprehend without reading the whole book.
You can explain AI to a 5-year-old by telling them that AI is like a computer
having a small brain. AI is like enabling a computer to have human-like intelligence,
not in terms of simple repetitive tasks but of human cognitive functions.
For example, AI can help a computer recognize people, objects, animals, or places.
More summarization questions on the book,
Who are the AI leaders in the book?
The book features 60 leaders from a variety of backgrounds and standpoints,
including academics, business leaders, technologists, authors, and researchers.
Some of the AI leaders featured in the book include Professor Andy Pardoe,
Harry Mamangakis, Agnis Stibe, Richard Benjamins, Jair Ribeiro, Jordi Guitart, PhD,
Dr. Sunil Kumar Vuppala, and John Thompson.
What is the most unusal ideas that can disrupt the society?
The idea of digitally modified citizens and intelligently-controlled societies,
enabled by advancements in Artificial Intelligence, could result in a paradigm shift
in our society.
Resume Question and Answering
If we pause and return later, we don’t have to start from scratch to access the Pinecone index. Instead, we can connect to the existing index to begin.
# use existing Pinecone index
docsearch = Pinecone.from_existing_index(index_name, embeddings, namespace=namespace)
What we have covered so far is just the initial steps in building a question answering system to understand a book. There are many other steps that we could take to improve the system and make it more effective. For example, we could improve the accuracy of our system by training it on a larger dataset of questions and answers. We could also fine-tune the OpenAI model on a specific domain (e.g., history, science, etc.) to improve its performance on questions related to that domain.
Concluding Remarks
The modern AI technologies have greatly expanded our ability to analyze and extract valuable insights from large volumes of text data, such as books or documents. Through the use of tools like OpenAI, LangChain, and Pinecone, we can perform sophisticated searches on this data, allowing us to quickly and efficiently find the information we need. Additionally, by chunking the data into smaller, more manageable pieces, we can provide contextual information to AI models, improving their ability to process and analyze the information we present to them.
Although this article provides a successful experimental system for question answering, building a high-performance and robust system that can cater to a wide range of use cases and deliver improved accuracy and reasoning power requires the expertise of seasoned system developers like us.
With our extensive knowledge and experience in this domain, we provide tailored solutions that not only meet but exceed the expectations of our enterprise clients. So if you’re looking to take your project to the next level, don’t hesitate to contact us. Remember, asking questions is always important and welcome. We’re here to help you build the best system possible!
References
- Data Independent, LangChain101: Question A 300 Page Book, video, Feb 2023.
- This article is greatly inspired by this video. It shows load a PDF book, split it up into documents, get vectors for those documents as embeddings, then ask a question.
- Matthew MacFarquhar, A.I. Wonderland: SparkNotes.ai with Langchain and OpenAI, Medium, Mar 2023.
- Creating an automatic SparkNotes bot which will answer our questions using only the text provided and will not make up things not found in the text. Alternatively, it used an in-memory Chroma DB for the index; that’s mean it was not persisted and needed to rebuild everytime.
-
Adler Mortimer and Charles Van Doren, How to Read a Book, Touchstone, Revised and Updated edition, Aug 1972, isbn: 978-0671212094.
- Big Think, The art of asking the right questions, video, Sep 2020.
- The difference between the right and wrong questions is not simply in the level of difficulty. In this video, geobiologist Hope Jahren, journalist Warren Berger, experimental philosopher Jonathon Keats, and investor Tim Ferriss discuss the power of creativity and the merit in asking naive and even “dumb” questions.
- Online Book, 60 Leaders on Artificial Intelligence, 2022.
Other Blog Post
-
Benny Cheung, Deep Learning on Text Data, Benny’s Mind Hack, Jul 2018.
-
Benny Cheung, Synthesis of Neural to Symbolic Knowledge for NLP System, Benny’s Mind Hack, Dec 2020.





