artwork by M.C. Escher - Metamorphosis II
Synthesis of Neural to Symbolic Knowledge for NLP System
Much of human knowledge is collected in the written language. Extracting knowledge directly from the textual form of natural language has been one of the lofty goals of Natural Language Processing (NLP) since the beginning of AI research. The recent advance in NLP, using deep neural networks, has effectively automated the parsing and understanding of the natural language. The NLP using deep neural networks is successful because of the DNN adaptive learning ability to handle real-world data when the processing is not readily describable in the traditional symbolic rules.
[2024/10/05] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/synthesis-neural-symbolic-knowledge-nlp/Podcast_Neural_Symbolic_AI.mp3
Our past exploration on “Deep Learning on Text Data” has demonstrated the basics of NLP using DNN. In this article, we shall take another leap into the next stage of NLP. After the NLP accurately parsed the text, a dependency graph can be computed. To improve human-level understanding, we can use the traditional symbolic reasoning.
The combination of symbolic AI and emerging NLP tools that recently evolved from deep neural network researches start to mature. We believe that this high-level symbolic reasoning and low-level statistical learning are complementary according to AI experts [Launchbury17]. By working them together, they will take significant forward steps in natural language understanding. Subsequently, humans can use the symbolic explanation to understand the AI model’s reasoning and to improve the human-machine interactions.
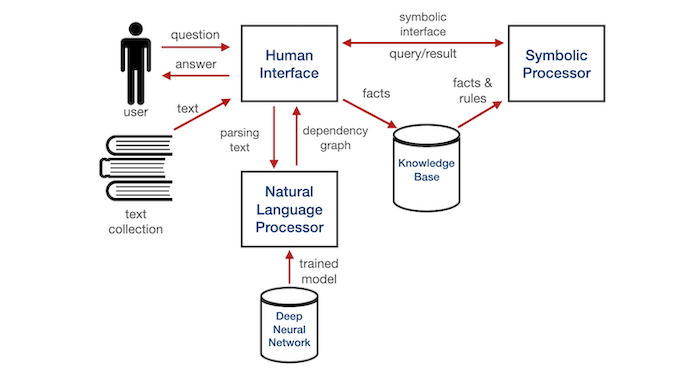 Figure. Neural to Symbolic NLP system architecture shows the synergies between low-level NLP and high-level symbolic processor. By encoding the low-level parsed text into symbolic representations, human interaction can be improved by the traceable questions and answers in symbolic reasoning.
Figure. Neural to Symbolic NLP system architecture shows the synergies between low-level NLP and high-level symbolic processor. By encoding the low-level parsed text into symbolic representations, human interaction can be improved by the traceable questions and answers in symbolic reasoning.
In the Neural to Symbolic NLP system architecture diagram, the future of NLP is componentized into the Natural Language Processor which has the dedicated responsibility of parsing the text accurately and flexibly with deep neural networks. The text collection is transformed into facts and rules such that the Symbolic Processor can apply high-level reasoning to the Knowledge Base of the transformed facts and rules. Furthermore, tapping into the wealth of Data Mining and Knowledge-Based Management System (KBMS), we understand how to make a large number of facts usable in AI reasoning tasks. If the human level of symbolic facts is fed into the rule-based system, the reasoning engine can search either backward-chaining or forward-chaining through a set of domain-specific rules [GiarratanoRiley04]. The most important business value is to ensure that the reasoning steps are traceable and explainable based on the original truthful observation from the human context.
This may look like another AI pipe dream but we shall take a practical engineering step using DeepRank [TarauBlanco20] to demonstrate the possibility. We start with the synthesis of neural to symbolic knowledge from a simple document to perform question and answer; subsequently, we shall synthesize knowledge from a complex HIPAA regulations document to illustrate the greater system capabilities.
Synthesis of Neural to Symbolic Knowledge
Knowledge engineering is the process of creating both facts and rules that apply to data to imitate the way a human thinks and approaches problems. A task and its solution are broken down into their structure and based on that information, the reasoning engine determines how the solution was reached. Traditionally, the knowledge engineering process requires a domain expert working with a knowledge engineer to manually encode the domain facts and rules into the knowledge base. The process is usually very expensive and slow.
Luckily, in the domain of text documents, we can rely on the implicit textual data to state the facts about its content, i.e. the content is the domain expert by itself. All we need to do is to find the best knowledge representation to state the collection of implicit facts. The rules are more tricky; however, we can always start with the generic textual understanding by the language grammar and the statement context.
We recognize the limitations of the current proposed techniques [CS224N].
- We still have primitive methods for building and accessing memories or knowledge.
- Current models have almost nothing for developing and executing goals and plans.
- We still have quite inadequate abilities for understanding and using inter-sentential relationship.
- We still can’t, at a large scale, do elaborations from a situation using common sense knowledge.
The former list is not impossible to tackle but we are not covering them here.
Using DeepRank
We are utilizing the recent research by DeepRank [TarauBlanco20]. The system uses a Python-based text graph processing algorithm together with the Prolog-based symbolic reasoning engine into a unified high-level text processor for human interface, capable of textual question and answer. DeepRank’s backend connects as a Python client to the Stanford CoreNLP server [ChenManning14] and uses it to provide the low-level text parsing result of dependency graphs. DeepRank can generate the summary, keyphrase and other relations as the extracted facts that constitute the logical model of the textual document, subsequently to be processed by the symbolic reasoning engine.
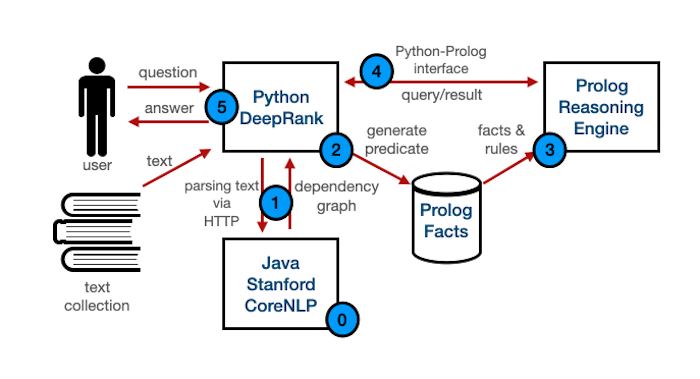 Figure. DeepRank system architecture. The system is open source (see the References section)
Figure. DeepRank system architecture. The system is open source (see the References section)
For introduction, we shall start simple with the test.txt, which is about Socrates & Plato relationship in 3 sentences.
Socrates did not write any books.
Plato is a student of Socrates.
Plato wrote books and put words into Socrates mouth.
The following sections will describe each step of the workflow shown in the DeepRank system architecture diagram,
- (0) Starting Stanford CoreNLP Server
- (1) DeepRank Text Parsing
- (2) Generate the Prolog Facts
- (3) Loading Facts & Rules into Prolog
- (4) DeepRank Query Processing
- (5) Reasoning in Prolog to Provide Answers
0. Starting Stanford CoreNLP Server
The Stanford CoreNLP dependency parser [ChenManning14] stands out, producing highly accurate dependency graphs. The vertices in these graphs are words and their part-of-speech tags, and labeled edges indicate the syntactic heads of words (e.g., subject, direct object).
Download Stanford CoreNLP Java Server
- required version 3.9.2, 2018-10-05 release to work
- unzip into the directory
stanford-corenlp-full-2018-10-05, wherestart_server.shscript will look for the jar file.
We shall start the Java-based Stanford CoreNLP server in a shell window,
java -mx16g -cp "stanford-corenlp-full-2018-10-05/*" \
edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-preload tokenize,ssplit,pos,lemma,ner,parse,depparse \
-status_port 9000 -port 9000 -timeout 30000 -quiet
Please noted that we have requested to preload the list of annotators for the parsing results,
-preload tokenize,ssplit,pos,lemma,ner,parse,depparse
1. DeepRank Text Parsing
We can start by importing the Python-based DeepRank main interface. The params will control the system configurations.
from textcrafts import deepRank as dr
from textcrafts.sim import *
from textcrafts.vis import *
from textcrafts.parser_api import *
class talk_params(dr.craft_params):
def __init__(self):
super().__init__()
self.corenlp = True
self.quiet = True
self.summarize = True
self.quest_memory = 1
self.max_answers = 3
self.repeat_answers = 'yes'
self.by_rank = 'no'
self.personalize = 30
self.show=True
self.cloud=36
params=talk_params()
Then, we create the GraphMaker object and give it the params.
fName='test.txt'
fNameNoSuf = 'examples/{}'.format(fName)
gm=dr.GraphMaker(params=params)
gm.load(fNameNoSuf+'.txt')
Once the given document is parsed by the DeepRank’s backend Stanford CoreNLP, it returns the dependency graph and all the requested annotations.
print(gm)
To gain the summary insight of the dependency graph, print(gm) showing the following characteristics,
--- GraphMaker object ---
nodes: 20
edges: 41
--- KEYPHRASES ---
Socrates;
student;
book;
Plato;
word;
--- SUMMARY ---
0 : Socrates did not write any books .
1 : Plato is a student of Socrates .
2 : Plato wrote books and put words into Socrates mouth .
--- RELATIONS ---
('Socrates', 'write', 'book', 0)
('Plato', 'write', 'book', 2)
Word Cloud for Keywords Ranking
More interestingly, we can use the Word Cloud to visualize all the keywords ranking
gm.kshow(params.cloud,file_name="{}_cloud.jpg".format(fName),show=True)
img = mpimg.imread('{}_cloud.jpg'.format(fName))
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(img)
Socrates has been identified as the highest ranked keyword as expected.

Ranked Dependency Graph
DeepRank is using the PageRank implementation of the networkx toolkit.
After ranking the sentence and word nodes of the dependency graph,
the system is also able to display subgraphs filtered to contain only the highest ranked nodes,
using Python’s graphviz library.
B = dr.best_line_graph(32,gm)
gshow(B, file_name="{}.gv".format(fName), attr="rel")
Then we can plot the ranked dependency graph,
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('{}.gv.png'.format(fName))
fig, ax = plt.subplots(figsize=(16, 16))
ax.imshow(img)
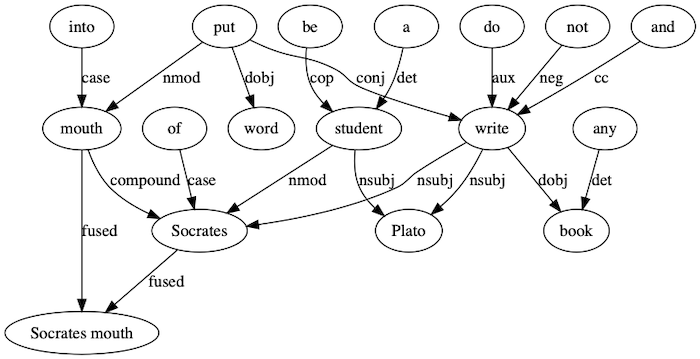
The dependency graph’s edges are annotated using the Universal Dependencies Treebank Tags.
Stanford CoreNLP evolution towards the use of Universal Dependencies makes systems relying on it potentially portable to over 70 languages covered by the Universal Dependencies effort.
2. Generate the Prolog Facts
Collecting the dependency graph and annotations together, they can be translated into a Prolog facts representing the content of the document.
from deep_talk.qpro import *
to_prolog('', gm, gm, fNameNoSuf, params=params)
The following predicates are generated in the form of Prolog-readable code in a file:
- keyword(WordPhrase). – the extracted keyphrases
keyword('Socrates').
keyword('student').
...
- summary(SentenceId,SentenceWords). – the extracted summary sentence identifiers and list of words in sentence
summary(0, ['Socrates', 'did', 'not', 'write', 'any', 'books', '.']).
summary(1, ['Plato', 'is', 'a', 'student', 'of', 'Socrates', '.']).
...
- dep(SentenceID,WordFrom,FromTag,Label,WordTo,ToTag). – a component of a dependency link, with the first argument indicating the sentence they have been extracted
dep(0, 'write', 'VB', 'nsubj', 'Socrates', 'NNP').
dep(0, 'write', 'VB', 'aux', 'did', 'VBD').
...
- edge(SentenceID,FromLemma,FromTag,RelationLabel,ToLemma,ToTag).–edge marked with sentence identifiers indicating where it was extracted from, and the lemmas with their POS tags at the two ends of the edge
edge(0, 'write', 'VB', 'nsubj', 'Socrates', 'NNP').
edge(0, 0, 'SENT', 'about', 'Socrates', 'NNP')
...
- rank(LemmaOrSentenceId,Rank). – the rank computed for each lemma
rank('Socrates', 0.13106262484911943).
rank('student', 0.10238177148979816).
...
- w2l(Word,Lemma,Tag). – a map associating to each word a lemma and a tag, as found by the POS tagger
w2l('Socrates', 'Socrates', 'NNP').
w2l('books', 'book', 'NNS').
w2l('wrote', 'write', 'VBD').
...
- svo(Subject,Verb,Object,SentenceId). – subject-verb-object relations extracted from parser input or WordNet-based is a and part of labels in verb position
svo('Socrates', 'write', 'book', 0).
svo('Plato', 'write', 'book', 2)
...
- ner(SentId,ListOfNamedEntityPairs) - extracted from Named Entity Recognizer(NER) annotations
ner(0, [(0, ('Socrates', 'PERSON'))]).
ner(1, [(0, ('Plato', 'PERSON')), (1, ('student', 'TITLE')), (2, ('Socrates', 'PERSON'))]).
ner(2, [(0, ('Plato', 'PERSON')), (1, ('Socrates', 'PERSON'))])
- sent(SentenceId,ListOfWords). – the list of sentences in the document with a sentence identifier as first argument and a list of words as second argument
sent(0, ['Socrates', 'did', 'not', 'write', 'any', 'books', '.']).
sent(1, ['Plato', 'is', 'a', 'student', 'of', 'Socrates', '.']).
sent(2, ['Plato', 'wrote', 'books', 'and', 'put', 'words', 'into', 'Socrates', 'mouth', '.']).
These predicates provide a relational view of a document in the form of a fact database that will support the inference mechanisms built on top of it.
3. Loading Facts & Rules into Prolog
PySwip is a (Python - SWI-Prolog) bridge enabling to query SWI-Prolog in the Python programs. It features an SWI-Prolog foreign language interface, a utility class that makes it easy querying with Prolog and also a Pythonic interface.
Installation on Mac
We can get the version of SWI-Prolog 7.6.4 and install it.
On Mac, pyswip only work with SWI-Prolog (threaded, 64 bits, version 7.6.4)
pip install pyswip
Make sure swipl executable is on the PATH and the directory that contains libswipl.dylib is in
the DYLD_FALLBACK_LIBRARY_PATH environment variable.
For example, if SWI-Prolog is installed at /Applications/SWI-Prolog.app directory, the following may work:
export PROLOG_HOME="/Applications/SWI-Prolog.app/Contents"
export PATH="$PATH:${PROLOG_HOME}/swipl/bin/x86_64-darwin15.6.0"
export DYLD_FALLBACK_LIBRARY_PATH="${PROLOG_HOME}/swipl/lib/x86_64-darwin15.6.0":${DYLD_FALLBACK_LIBRARY_PATH}
After the pyswip has been setup, we are ready to load the facts and rules into SWI-Prolog.
The default companion rules are included in deep_talk/qpro.pro.
The rules are used to perform the matching and reasoning of the query against the document facts.
from pyswip import *
from pyswip.easy import *
# finds absolute file name of Prolog companion rules qpro.pro
def pro() :
return 'deep_talk/qpro.pro'
def sink(generator) :
for _ in generator : pass
prolog = Prolog()
sink(prolog.query("consult('" + pro() + "')"))
sink(prolog.query("load('"+fNameNoSuf+"')"))
After this executed, the facts and rules is loaded into SWI-Prolog.
4. DeepRank Query Processing
We can formulate a question (aka. query) to the knowledge base. For example, the question:
Who is Plato's teacher?
The query will be parsed.
question="Who is Plato's teacher?"
qgm=dr.GraphMaker(params=params)
qgm.digest(question)
qfName=fNameNoSuf+'_query'
to_prolog('query_', gm, qgm, qfName,params=params)
Like the document, we can visualize the query Word Cloud’s keywords ranking.
img = mpimg.imread('query_cloud.jpg')
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(img)
The query is center around Plato keyword as expected.

The query will be parsed and generated the corresponding query’s dependency graph
img = mpimg.imread('query_graph.gv.png')
fig, ax = plt.subplots(figsize=(10, 10))
ax.imshow(img)
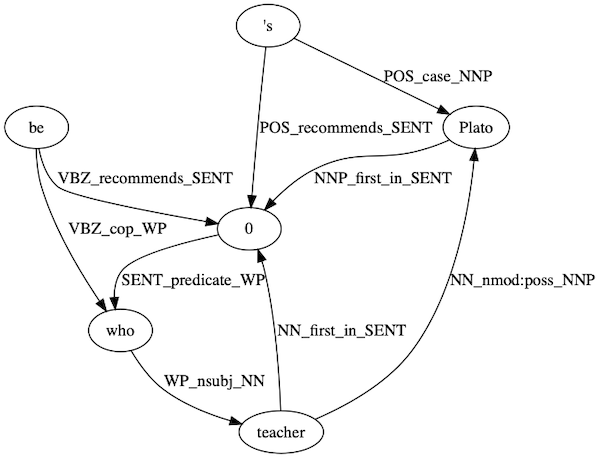
5. Reasoning in Prolog to Provide Answers
It activates a Prolog process to which Python sends interactively queries about a selected document.
Answers are computed by Prolog and then, if the say OS-level facility is available (on OS X and Linux machines), the system will actually speak the answers.
import subprocess
def say(what) :
print(what)
subprocess.run(["say", what])
rs=prolog.query("ask('" + fNameNoSuf + "'" + ",Key)")
answers=[pair['Key'] for pair in rs]
if not answers: say("Sorry, I have no good answer to that.")
else :
for answer in answers :
say(answer)
Finally, DeepRank will response with the top ranking answers. The results are sensible.
1 : Plato is a student of Socrates .
2 : Plato wrote books and put words into Socrates mouth .
HIPAA Regulations
We will use the Health Insurance Portability and Accountability Act (HIPAA) in the US as a more intensive example. HIPAA regulates the transfer of patient medical information, depending on the type of disclosure and patient consent. Not only we shall see the knowledge engineering process is capable to handle a complex and intertwined regulation document, it is now possible to explain how the answer is derived.
Example: HIPAA Rule - 164.508
To help the later description, let’s read a small excerpt from HIPAA rule 164.508 - Uses and disclosures for which an authorization is required. We can see the full text at Cornell19.
(a) Standard: Authorizations for uses and disclosures -
(1) Authorization required: General rule. Except as otherwise permitted or required by this subchapter, a covered entity may not use or disclose protected health information without an authorization that is valid under this section. When a covered entity obtains or receives a valid authorization for its use or disclosure of protected health information, such use or disclosure must be consistent with such authorization.
(2) Authorization required: Psychotherapy notes. Notwithstanding any provision of this subpart, other than the transition provisions in § 164.532, a covered entity must obtain an authorization for any use or disclosure of psychotherapy notes, except:
(i) To carry out the following treatment, payment, or health care operations:
(A) Use by the originator of the psychotherapy notes for treatment;
(B) Use or disclosure by the covered entity for its own training programs in which students, trainees, or practitioners in mental health learn under supervision to practice or improve their skills in group, joint, family, or individual counseling; or
(C) Use or disclosure by the covered entity to defend itself in a legal action or other proceeding brought by the individual; and
(ii) A use or disclosure that is required by § 164.502(a)(2)(ii) or permitted by § 164.512(a); § 164.512(d) with respect to the oversight of the originator of the psychotherapy notes; § 164.512(g)(1); or § 164.512(j)(1)(i)
...
Following the same workflow as the starter example, we are using DeepRank to ingest this HIPAA document. The Word Cloud shows a great summarization of the important keywords in the document.

Of course, the dependency graph is looking a lot more intensive with more nodes and edges, and their interconnectivity.

Let’s test the system with a relevant HIPAA question of,
What must be done before disclosing protected health information?
The query’s Word Cloud shows a great summarization of the important keywords for the finding the answers.

The generated query’s dependency graph will be translated into Prolog query to match against the document facts.
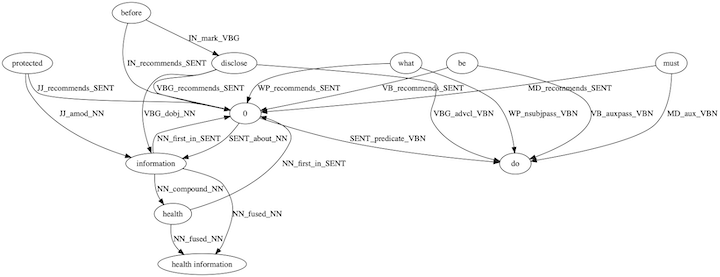
Finally, the answers are all appropriate and good, surrounding the requirement to get authorization before the disclosure.
2 : Except as otherwise permitted or required by this subchapter , a covered entity may not use or disclose protected health information without an authorization that is valid under this section .
9 : ( 4 ) Authorization required : Sale of protected health information .
43 : ( iii ) The potential for information disclosed pursuant to the authorization to be subject to redisclosure by the recipient and no longer be protected by this subpart .
Concluding Remarks
This is exciting to use DeepRank, demonstrating the synthesis of neural to symbolic knowledge from any document. We can see the strategy of combining both deep neural network NLP and symbolic reasoning is effective even it has limitations. To move towards the greater AI natural language understanding goals, the system needs to improve on,
- Abilities for understanding and using inter-sentential relationship.
- Abilities for elaborating from a situation using common sense knowledge.
The research team providing the Stanford CoreNLP is definitely improving on the inter-sentential relationship building with the latest neural network techniques. To build a better common sense into the knowledge base, which supports generalized concepts and a wider range of reasoning rules, we can look upon Douglas Lenat’s Cyc project for the research insights.
References
- [ChenManning14] Danqi Chen and Christopher Manning, A Fast and Accurate Dependency Parser using Neural Networks, 2014, In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 740–750.
- [Cornell19] Cornell Law School (2019), Legal Information Institute, Digital version of 164.508
- website at: https://www.law.cornell.edu/cfr/text/45/164.508
- [CS224N] Christopher Manning, Stanford CS224N: NLP with Deep Learning, Winter 2019
- Excellent lecture series on NLP with Deep Learning.
- website at: http://www.stanford.edu/class/cs224n/
- video at: https://www.youtube.com/watch?v=8rXD5-xhemo&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
-
[GiarratanoRiley04] Giarratano J, Riley G. (2004), Expert Systems: Principles and Programming, Fourth Edition, Course Technology, ISBN: 978-0534384470
- [Launchbury17] Launchbury J. (2017), A DARPA Perspective on Artificial Intelligence
- [LamMitchell18] Lam P.E., Mitchell J.C., Sundaram S. (2018) A Formalization of HIPAA for a Medical Messaging System. In: Fischer-Hübner S., Lambrinoudakis C., Pernul G. (eds) Trust, Privacy and Security in Digital Business. TrustBus 2018. Lecture Notes in Computer Science, vol 5695. Springer.
- [TarauBlanco20] Paul Tarau and Eduardo Blanco, Interactive Text Graph Mining with a Prolog-based Dialog Engine, July 2020, Intl. Symposium on Practical Aspects of Declarative Languages, pp 3-19.
- paper at: https://arxiv.org/pdf/2008.00956
- The open-source code of the integrated system is available at https://github.com/ptarau/DeepRank





