artwork by Stable Diffusion AI
Create Personal Animated AI Avatar
Creating your personal AI avatar can be a fun and exciting way to explore the capabilities of cutting-edge AI technologies. An AI avatar is a digital representation of a person that is created using artificial intelligence (AI) tools and techniques. It can take many forms, such as a 3D model, an animated character, or a virtual assistant. AI avatars are becoming increasingly popular in areas such as gaming, entertainment, virtual assistants, and social media.
[2024/10/05] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/create-personal-animated-ai-avatar/Podcast_Personal_AI_Avatar.mp3
The potential reasons why we might want to create an AI avatar include:
- Gaming: We could create an avatar to represent user in a video game, giving user a more personalized gaming experience.
- Social media: An AI avatar can serve as a unique and eye-catching profile picture on social media platforms.
- Virtual assistants: We could create an avatar to serve as a virtual assistant, which could respond to voice commands and help user with tasks such as scheduling appointments or customer supports.
In this article, we will walk through the process of creating a personal AI avatar using bleeding edge AI tools, such as Stable Diffusion, ChatGPT, ElevenLabs, and D-ID. Subsequently, we also looked at the data models and class structures required to create an animated chatbot system, and how user input is processed and classified to generate appropriate responses.
![]() Figure. Illustrated the animated AI avatar creation workflow. (1) Generating avatar picture using Stable Diffusion (2) Generating text using ChatGPT (3) Generating a voice using ElevenLabs (4) Combining your avatar picture and generated voice using D-ID.
Figure. Illustrated the animated AI avatar creation workflow. (1) Generating avatar picture using Stable Diffusion (2) Generating text using ChatGPT (3) Generating a voice using ElevenLabs (4) Combining your avatar picture and generated voice using D-ID.
For example, See my personal AI avatar in action: Animated Personal AI Avatar Demo
Figure. Demo of an animated personal AI avatar.
To learn how to train a personal model for Stable Diffusion, read our previous posts on the topics:
Step 1: Generating an avatar picture using Stable Diffusion
Stable Diffusion is a state-of-the-art AI tool that can be used to generate high-quality images of faces. To use Stable Diffusion, you need to provide it with some starting parameters, such as gender, age, and hairstyle, and it will generate a realistic image of a face that matches those parameters.
To generate your personal avatar picture, start by building a personal embedding described in our previous post on Dreambooth Training for Personal Embedding. You can choose any combination of parameters that you like, depending on the kind of avatar that you want to create. Once you have chosen your parameters, run Stable Diffusion to generate your avatar picture.
Prompt: bennycheung person is the token of our personal embedding model
bennycheung person as a fantasy character, ultra realistic, intricate, elegant,
highly detailed, 8k, digital painting, detailed background, trending on artstation,
smooth, sharp focus, illustration, in the style of wlop, greg rutkowski
Negative Prompt: that’s right, we need to tell a lot to Stable Diffusion NOT to do!
(((wrinkle))), bread, hat, disfigured, kitsch, ugly, oversaturated, grain,
low-res, Deformed, burry, bad anatomy, disfigured, poorly drawn face, mutation,
mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs,
disconnected limbs, malformed hands, bur, out of focus, long neck, long body, ugly,
disgusting, poorly drawn, childish, mutilated, mangled, old, surreal, text, blurry,
b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms,
fashion photos (collage:1.25), meme, deformed, elongated, twisted, fingers,
strabismus, heterochromia, closed eyes, blurred, watermark, wedding, group
![]()
Figure. Use Stable Diffusion (via AUTOMATIC1111 Web UI) to generate the avatar image from a prompt.
Step 2: Generating text using ChatGPT
ChatGPT is a powerful natural language processing (NLP) tool that can be used to generate text based on a given prompt. To use ChatGPT, you need to provide it with a prompt, and it will generate a piece of text that follows from that prompt.
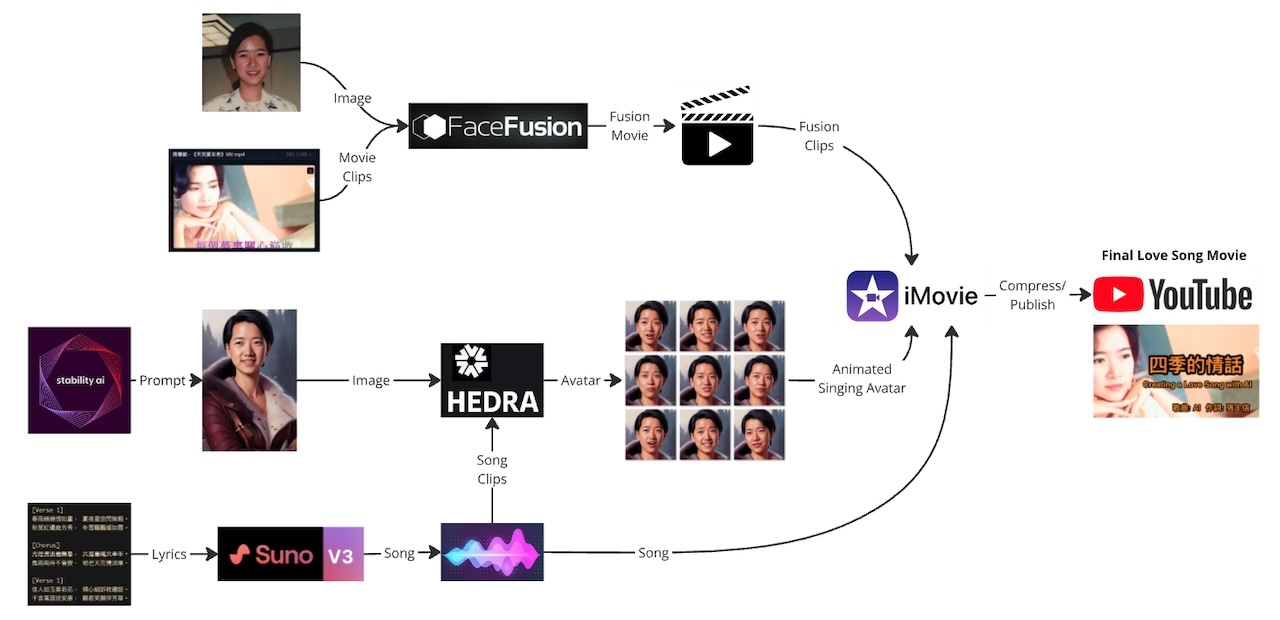
To generate the script for your AI avatar, start by choosing a prompt that will help you to create the kind of dialogue that you want your avatar to have. For example, you might choose a prompt like “Introduce yourself” or “Tell me about your interests.” Once you have chosen your prompt, run ChatGPT to generate the script.
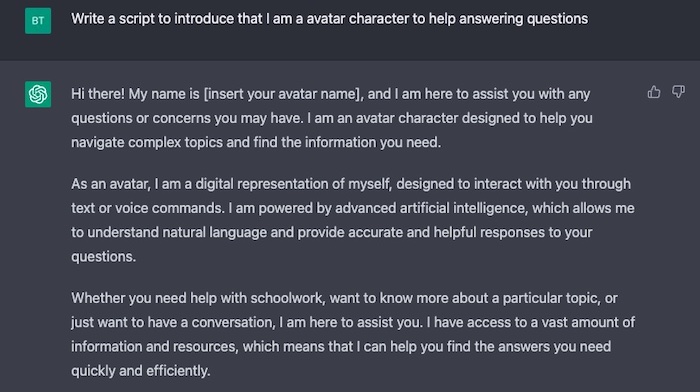
Figure. Use ChatGTP to write a script for the avatar speech.
Step 3: Generating a voice using ElevenLabs
ElevenLabs is a cutting-edge AI tool that can be used to generate realistic voices based on a given text. To use ElevenLabs, we need to provide it with a text script, and it will generate a voice that speaks the text in a natural and realistic way. We can rely on ElevenLabs supplying some free credits to get started.
To generate the voice for your AI avatar, start by providing ElevenLabs with the script that we generated using ChatGPT. ElevenLabs will use advanced deep learning techniques to generate a voice that matches the script.
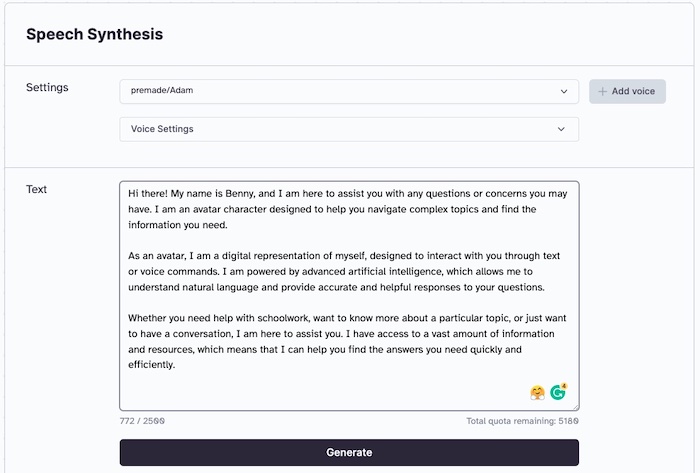
Figure. Use ElevenLabs to set the voice and the input script, to generate a MP3 audio file
Process of Voice Generation Explained
The process of generating a realistic voice involves several technical steps:
Step 1: Text analysis - The input text is first analyzed using natural language processing (NLP) algorithms to extract key features such as syntax, semantics, and prosody. This analysis helps to understand the structure and content of the text, including the tone, style, and intended emotion.
Step 2: Acoustic modelling - Once the input text is analyzed, ElevenLabs uses deep learning techniques to train an acoustic model based on the text. The acoustic model is a neural network that learns to map the text to the corresponding acoustic features of speech, such as pitch, volume, and duration.
Step 3: Voice synthesis - After training the acoustic model, ElevenLabs uses a synthesis algorithm to generate the corresponding voice waveform. The synthesis algorithm uses the acoustic model to generate a sequence of acoustic features, which are then converted into a continuous waveform using a vocoder. The vocoder is a neural network that converts the acoustic features into a high-quality audio signal that closely resembles natural human speech.
Step 4: Post-processing - Finally, ElevenLabs applies post-processing techniques to further enhance the quality and naturalness of the generated voice. These techniques can include filtering, noise reduction, and pitch shifting, among others.
ElevenLabs uses a combination of advanced NLP algorithms, deep learning techniques, and signal processing to generate high-quality, realistic voices from input text. This tool has a wide range of applications, including virtual assistants, audiobook narration, voiceovers for videos, and more.
Step 4: Combining your avatar picture and generated voice using D-ID
D-ID is a sophisticated AI tool that can be used to combine an image with a voice to create a realistic video of a person speaking. To use D-ID, we need to provide it with an image and a voice, and it will generate a video of the person in the image speaking with the given voice. We can rely on D-ID providing some free credits to get started.
To create a personal AI avatar, start by providing D-ID with your personal avatar picture and the voice that we generated using ElevenLabs. D-ID will use advanced computer vision and NLP techniques to create a video of our AI avatar speaking with a realistic voice.
Figure. Use D-ID to upload the generated audio file, and add the custom avatar image to generate video
Process of Video Generation Explained
The process of combining an image with a voice to create a realistic video involves several technical steps:
Step 1: Face detection and alignment - D-ID first detects the face in the input image and aligns it with a neutral position. The tool uses facial landmark detection algorithms to accurately identify and locate key facial features, such as the eyes, nose, and mouth, which are essential for generating realistic facial movements during speech.
Step 2: Lip-syncing - Once the face is aligned, D-ID generates realistic lip movements to synchronize with the given voice. The tool uses a combination of deep learning techniques and computer vision algorithms to analyze the voice and generate corresponding lip movements that match the sound.
Step 3: Facial expression generation - D-ID also generates realistic facial expressions based on the input voice. It uses NLP algorithms to analyze the speech content and generate corresponding emotional expressions, such as smiling, frowning, or raising eyebrows, that are consistent with the speech content.
Step 4: Video rendering - Finally, D-ID combines all the generated elements, such as the lip movements, facial expressions, and voice, to create a realistic video of the person speaking. The tool uses advanced computer graphics techniques to render the video with high-quality visuals and seamless lip-syncing.
D-ID uses a combination of sophisticated AI algorithms and techniques to generate realistic videos of people speaking based on images and voices. The tool can be used for a wide range of applications, such as creating personalized video messages, generating avatars for virtual assistants, or enhancing video conferencing experiences.
Animated Chat Bot Design
If we want to design a Chat Bot that combines the techniques of generating an avatar and a voice to interact with users can be achieved through a system design that includes the following components:
-
User Interface: The first component of the system design is the user interface, which allows users to interact with the Chat Bot. This can be in the form of a web or mobile application, or even a chat widget embedded on a website. Users can input text messages or voice commands through the user interface, which the Chat Bot will process and respond to.
-
Natural Language Processing (NLP): The second component of the system design is natural language processing, which is used to understand the input messages from the user. The NLP component will use techniques such as text analysis, sentiment analysis, and intent recognition to understand the meaning behind the user’s input.
-
Avatar Generation: The third component of the system design is the avatar generation, which uses a tool like Stable Diffusion to create a realistic image of the Chat Bot. The avatar can be customized to fit the branding or personality of the Chat Bot, and can even include facial expressions and lip movements generated by D-ID.
-
Voice Generation: The fourth component of the system design is voice generation, which uses ElevenLabs to generate a realistic voice for the Chat Bot. The voice can be customized to fit the branding or personality of the Chat Bot, and can even include emotional tones and inflections based on the input text.
-
Dialogue Management: The fifth component of the system design is dialogue management, which is responsible for managing the flow of the conversation between the user and the Chat Bot. This component uses a tool like ChatGPT to generate responses based on the input from the user and the current context of the conversation.
-
Integration and Deployment: The final component of the system design is the integration and deployment of the Chat Bot. This includes integrating all the components into a cohesive system, testing and validating the Chat Bot, and deploying it to a production environment.
The system design for a Chat Bot that combines avatar and voice generation would include components for user interface, NLP, avatar and voice generation, dialogue management, and integration and deployment. The combination of these components would create a highly personalized and engaging experience for users, enhancing the overall user experience and satisfaction.
Animated Chat Bot
To further the Chat Bot feature that uses an animated avatar to provide the response, would function similarly to a text-based (or voice only) Chat Bot, but with the added element of an animated visual representation of the Chat Bot.
When the user inputs a message or command, the Chat Bot will use natural language processing (NLP) to understand the user’s intent and generate an appropriate response. The response will then be translated into text, which will be used as the basis for generating an animated response from the Chat Bot’s avatar.
To achieve this, the Chat Bot will use an avatar generation tool like Stable Diffusion to create a realistic animated image of the Chat Bot. The avatar can be customized to match the branding or personality of the Chat Bot and can include a range of facial expressions, movements, and gestures.
Once the avatar has been generated, it will be integrated into the Chat Bot’s interface, which the user will see when receiving a response. The avatar’s movements, gestures, and expressions will be synchronized with the response text generated by the Chat Bot, creating a more engaging and personalized experience for the user.
System Design
From the user interface, the message or command would be passed on to the natural language processing (NLP) component, which would analyze the input to understand the user’s intent and generate a response. The response generated by the NLP component would be passed on to the avatar generation component, which would create an animated image of the Chat Bot in response to the user’s message or command.
Simultaneously, the response text generated by the NLP component would be passed on to the voice generation component, which would use ElevenLabs to generate a voice response from the Chat Bot. Both the avatar and voice responses would be passed back to the user interface, where the user could see and hear the Chat Bot’s response.
The dialogue management component would be responsible for managing the flow of the conversation, ensuring that the Chat Bot’s responses are appropriate and relevant to the current context. Finally, the entire system would be integrated and deployed to a production environment, where it could interact with users in real-time.
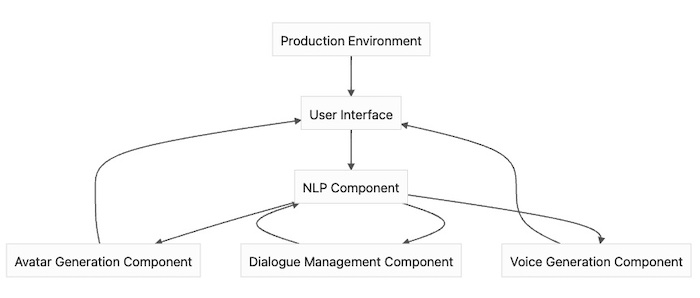
Figure. In this diagram, the User Interface (A) is connected to the NLP Component (B), which in turn is connected to both the Avatar Generation Component (C) and the Voice Generation Component (D). The Avatar Generation Component and Voice Generation Component both send their output back to the User Interface, and the Dialogue Management Component (E) is responsible for managing the flow of the conversation between the components. Finally, the entire system is integrated and deployed to a Production Environment (F).
System Data Model
The system data model can be summarized in the following table,
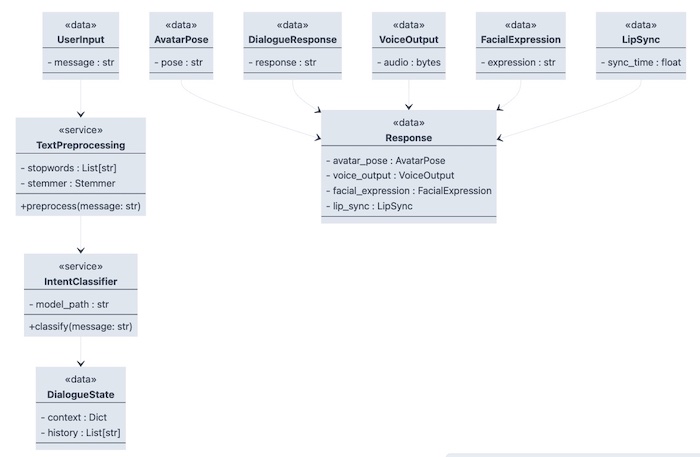
| Data Model | Description |
|---|---|
| User Input | The message or command entered by the user |
| Text Preprocessing | The NLP component processes the user input by removing stopwords, stemming, or lemmatizing |
| Intent Classification | The NLP component classifies the user input into one or more intent categories |
| Dialogue State | The current state of the conversation, including context and history |
| Avatar Pose | The current pose of the avatar, reflecting its emotions and physical state |
| Dialogue Response | The response generated by the Chatbot to answer the user’s request |
| Voice Output | The audio response generated by the Voice Generation Component based on the Dialogue Response |
| Facial Expression | The facial expression of the avatar, reflecting its emotions and tone of voice |
| Lip Sync | The synchronization between the voice output and the avatar’s lip movements |
| Response | The Chatbot’s final response, which includes both the Avatar Pose and the Voice Output |
This system data model represents the various components and data structures involved in the creation and response generation of a Chatbot. The user input is the starting point of the interaction and is processed by the Text Preprocessing component, which applies various NLP techniques to the input to make it easier to analyze.
The Intent Classification component then classifies the user input into one or more intent categories, which are used to determine the appropriate response. The Dialogue State component stores the current state of the conversation, including context and history, and is updated with each new user input.
The Avatar Pose component stores the current pose of the avatar, reflecting its emotions and physical state. The Facial Expression component uses this information to generate a facial expression that matches the tone and emotion of the voice output.
The Dialogue Response component generates the response to the user input, which is then passed to the Voice Output component. This component generates the audio response based on the Dialogue Response, which is synchronized with the Lip Sync component to ensure that the avatar’s lip movements match the audio.
Finally, the Response component combines the Avatar Pose and Voice Output to create the final response that is displayed to the user. Together, these components and data structures create a conversational experience that is engaging and responsive to the user’s needs.
Class Design
Here’s an example of the class data structures for each component data model can be layout as:
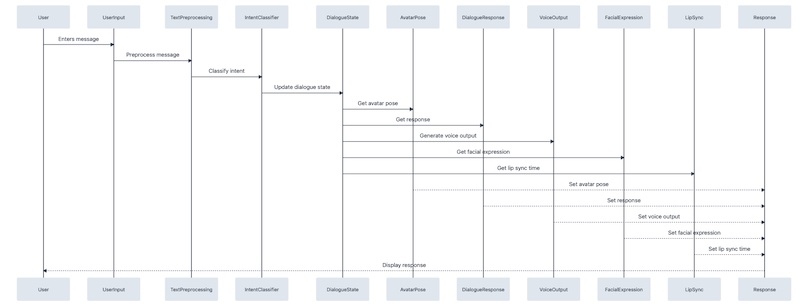
Here’s an example sequence diagram depicts how the user input would impact the classes mentioned above:
Concluding Remarks
In this article, we have explored the exciting world of AI avatars and chatbots. We discussed how cutting-edge AI tools and techniques such as Stable Diffusion, ChatGPT, ElevenLabs, and D-ID can be used to create an AI avatar that is realistic and interactive. We explored the technical details of how these tools and components work together to create a compelling conversational experience for users.
We also looked at the data models and class structures that are involved in creating an animated chatbot system, and how user input is processed and classified to generate appropriate responses. We examined the various components involved in generating the avatar’s facial expression and lip sync, as well as the voice output that is synchronized with the avatar’s movements.
We have seen that AI avatars and chatbots have enormous potential to revolutionize the way we interact with technology. With advances in AI technology, we can create more lifelike and engaging avatars that can enhance the user experience and provide new ways to connect with others. The possibilities are endless, and we can expect to see even more exciting developments in this field in the years to come.
References
- Prompt Engineering, Create Your Own AI Animated Avatar: A Step-by-Step Guide, Youtube, Feb 2023
- we learned how to create AI avatar with cutting-edge AI tools and techniques here. The AI avatar was created using MidJourney, ChatGPT, ElevenLabs, and D-ID.
Other Blog Posts
- Benny Cheung, Stable Diffusion Training for Personal Embedding, Benny’s Mind Hack, Nov 2022.
- Benny Cheung, Dreambooth Training for Personal Embedding, Benny’s Mind Hack, Nov 2022.
AI Tools
- ChatGPT for script creation: ChatGPT
- Stable Diffusion for image generation using Automatic1111: Stable Diffusion
- Elevenlabs for audio generation: Elevenlabs
- D-ID for video generation: D-ID