artwork by AI
Adventures in Deep Reinforcement Learning using StarCraft II
The paradigm of learning by trial-and-error, exclusively from rewards is known as Reinforcement Learning (RL). The essence of RL is learning through interaction, mimicking the human way of learning with an interaction with environment and has its roots in behaviourist psychology. The positive rewards will reinforce the behaviour that leads to it.
[2024/10/05] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/adventures-in-deep-reinforcement-learning/Podcast_Deep_Reinforcement_Learning_StarCraft_II.mp3
For a definition of the reinforcement learning problem we need to define an environment in which a perception-action-learning loop takes place. In this environment, the agent observes a given state t. The agent, learning in the policy, interacts with the environment by taking an action in a given state that may have long term consequences. It goes into a next state with a given timestep t+1 and updates the policy. At the end, the agent receives observations/states from the environment and a reward as a sign of feedback, and interacts with the environment through the actions.
The reinforcement learning problem can be described formally as a Markov Decision Process (MDP): it describes an environment for reinforcement learning, the surroundings or conditions in which the agent learns or operates. The Markov process is a sequence of states with the Markov property, which claims that the future is independent of the past given the present. The sufficiency of the last state makes that we only need the last state to evaluate the agent future choices. While deep neural network requires a lot of supervised training data, and inflexible about the modelled world changes. On the other hand, reinforcement learning can handle the world changes and maximize the current selection.
Using PySC2 helps to understand the practical aspect of reinforcement learning, rather than starting with toy example, the complexity of StarCraft II game is more realistic, the AI needs to balance resources, building, exploring, strategizing and fighting. The balance of multiple objectives and long term planning in order to win, makes the game felt realistic in complexity. The current techniques are mostly focus on single agent learning. The potential is to extend into multi-agents learning that applying collaborative game theory (Do you remember the movie “A Beautiful Mind”?)
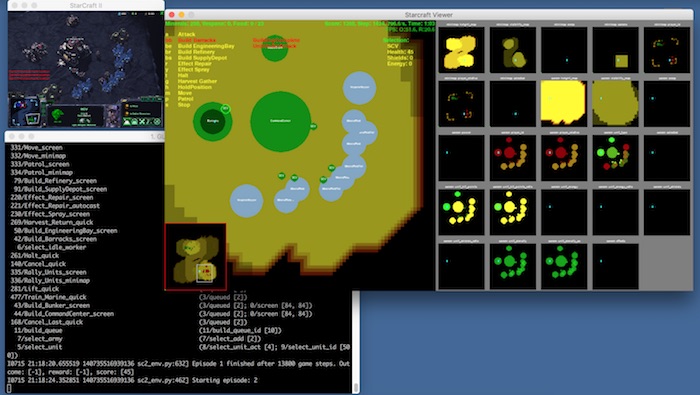
Figure. This shows the running state of the StarCraft II Learning Environment. The top left shows the actual StarCraft II game running. The SC2LE captures and reports the observations from the game environment. SC2LE allows a visual display of all the game observations on the right. The AI agent can take the observations and evaluates the optimal actions.
Games are ideal environments for reinforcement learning research. RL problems on real-time strategy (RTS) games are far more difficult than problems on Go due to complexity of states, diversity of actions, and long time horizon. The following is my practical research notes that capture this learning and doing process. This article is intended to provide a concise experimental roadmap to follow. Each section starts with a list of reference resources and then follows with what can be tried. Some information is excrept from the original sources for reader convenience, in particular being able to learn how to setup and running the experiements. As always, ability to use Python is fundamental to the adventures.
PySC2 Installation
- Ref: StarCraft II Learning Environment, https://github.com/deepmind/pysc2
- Ref: StarCraft II Client - protocol definitions used to communicate with StarCraft II https://github.com/Blizzard/s2client-proto
PySC2 is DeepMind’s Python component of the StarCraft II Learning Environment (SC2LE). It exposes Blizzard Entertainment’s StarCraft II Machine Learning API as a Python RL Environment. This is collaboration between DeepMind and Blizzard to develop StarCraft II into a rich environment for RL research. PySC2 provides an interface for RL agents to interact with StarCraft II, getting observations and sending actions.
Install by,
conda create -n pysc2 python=3.5 anaconda
conda activate pysc2
pip install pysc2==1.2
You can run an agent to test the environment. The UI shows you the actions of the agent and is helpful for debugging and visualization purposes.
python -m pysc2.bin.agent --map Simple64
There is a human agent interface that is mainly used for debugging, but it can also be used to play the game. The UI is fairly simple and incomplete, but it’s enough to understand the basics of the game. Also, it runs on Linux.
python -m pysc2.bin.play --map Simple64
Running an agent and playing as a human save a replay by default. You can watch that replay by running:
python -m pysc2.bin.play --replay <path-to-replay>
This works for any replay as long as the map can be found by the game. The same controls work as for playing the game, so F4 to exit, pgup/pgdn to control the speed, etc.
You can save a video of the replay with the --video flag
PySC2 Deep RL Agents
- Ref: Oriol Vinyals et. al., StarCraft II: A New Challenge for Reinforcement Learning, Aug 2017. https://arxiv.org/abs/1708.04782
- Ref: StarCraft II / PySC2 Deep Reinforcement Learning Agents (A2C) https://github.com/simonmeister/pysc2-rl-agents
This repository implements a Advantage Actor-Critic agent baseline for the pysc2 environment as described in the DeepMind paper StarCraft II: A New Challenge for Reinforcement Learning. It uses a synchronous variant of A3C (A2C) to effectively train on GPUs and otherwise stay as close as possible to the agent described in the paper.
Progress that confirmed by the project
- (/) A2C agent
- (/) FullyConv architecture
- (/) support all spatial screen and minimap observations as well as non-spatial player observations
- (/) support the full action space as described in the DeepMind paper (predicting all arguments independently)
- (/) support training on all mini games
Unfortunately, the project stopped before achieving the following objectives.
- (x) report results for all mini games
- (x) LSTM architecture
- (x) Multi-GPU training
Quick Install Guide
conda create -n pysc2 python=3.5 anaconda
conda activate pysc2
pip install --upgrade pip
pip install numpy
pip install tensorflow-gpu==1.4.0 --ignore-installed
pip install pysc2==1.2
Install StarCraft II. On Linux, use 3.16.1.
Download the mini games and extract them to your StarcraftII/Maps/ directory.
When you extract the zip files, you need to enter iagreetotheeula to accept the EULA.
Train & run
There are few more requirements to note.
- It requires cuda 8.0, cudnn 6.0 (tested on Linux 16.04 LTS, Titan-X 12 GB)
- Modify the following file
pysc2-rl-agents/rl/agents/a2c/agent.pyline 202, fromkeepdims=Truetokeep_dims=True
test with:
python run.py my_experiment --map MoveToBeacon --envs 1 --vis
run and train (the default spawning 32 environments are too many, reduced that to 16):
python run.py my_experiment --map MoveToBeacon --envs 16
run and evalutate without training:
python run.py my_experiment --map MoveToBeacon --eval
You can visualize the agents during training or evaluation with the --vis flag.
See run.py for all arguments.
Summaries are written to out/summary/<experiment_name> and model checkpoints are written to out/models/<experiment_name>.
After an hour of training on the MoveToBeacon mini-game, approx. 8K episodes, the agent can almost track the beacon optimally. (train on GPU TitanX Pascal (12GB))
![]()
In the following shows the plot for the score over episodes.
![]()
Understanding PySC2 Deep RL
- Ref: Gema Parreño, StarCraft II Learning environment full overview (series of 7 blogs)
- (III) Theory : Deep Reinforcement Learning Overview https://medium.com/@gema.parreno.piqueras/starcraft-ii-learning-environment-full-overview-iii-f7c2bc8cb4fb
- (IV) Theory : pySC2 environment https://medium.com/@gema.parreno.piqueras/starcraft-ii-learning-environment-full-overview-iv-2fb1a7c2667
- (V) Lab : Quickstart overview of pySC2 https://medium.com/@gema.parreno.piqueras/starcraft-ii-learning-environment-full-overview-v-34f5cb2a2220
- (VI) Lab : Jumping into the machine learning agent https://medium.com/@gema.parreno.piqueras/starcraft-ii-learning-environment-full-overview-vi-ae3126aa6b35
- (VII) Lab : Running and training the agent https://medium.com/@gema.parreno.piqueras/starcraft-ii-learning-environment-full-overview-vii-8b0775c1f3a7
- Ref: Gema Parreño, Startcraft II Machine Learning research with DeepMind pysc2 python library .mini-games and agents. https://github.com/SoyGema/Startcraft_pysc2_minigames
- Ref: Gema Parreño, Startcraft Pysc2 Deepmind mini games creation https://github.com/SoyGema/Startcraft_pysc2_minigames/tree/master/docs
Minigame task description
Minigames come as controlled environments that might be useful to exploit game features in StarCraft II. General purpose learning system for StarCraft II can be a daunting task. So there is a logical option in splitting this tasks into minitask in order to advance in research. Mini-games focus on different elements of StarCraft II Gameplay .
To investigate elements of the game in isolation, and to provide further fine-grained steps towards playing the full game, Deepmind has built several mini-games. These are focused scenarios on small maps that have been constructed with the purpose of testing a subset of actions and/or game mechanics with a clear reward structure. Unlike the full game where the reward is just win/lose/tie, the reward structure for mini-games can reward particular behaviours (as defined in a corresponding .SC2Map file).
Agents
Regarding scripted agent, there is a python file with several developments. scripted_agent.py is focused on HallucinIce map in which makes Archon Hallucination. Besides there is another class that put all hallucination actions on a list and the agent chooses randomly in between those actions.
Q-Learning and DQN agents are provided for HallucinIce minigame with the new PySC2 release
How to run mini-games in your environment
Download or clone the repository, or download all minigames clicking here
Place the .SC2 files into /Applications/StarCraft II/Maps/mini_games/ -sometimes the Map folder might not exist. If so, please create it-
Go to pysc2/maps/mini_games.py and add to mini-games array the following mini-games names
mini_games = [ ## This mini-games names should alredy been in your list
"BuildMarines", # 900s
"CollectMineralsAndGas", # 420s
"CollectMineralShards", # 120s
"DefeatRoaches", # 120s
"DefeatZerglingsAndBanelings", # 120s
"FindAndDefeatZerglings", # 180s
"MoveToBeacon", # 120s ##Now you add this few lines
"SentryDefense", # 120s
"ForceField", # 30s
"HallucinIce", # 30s
"FlowerFields", # 60s
"TheRightPath", # 300s
"RedWaves", # 180s
"BlueMoon", # 60s
"MicroPrism", # 45s
]
We can copy the sample from Starcraft_pysc2_minigames/Agents/scripted_agent.py to pysc2/agents/scripted_agent_test.py. Subsequently, we can test the scripted sample bot agents with the new mini-games. You should see something like the following.
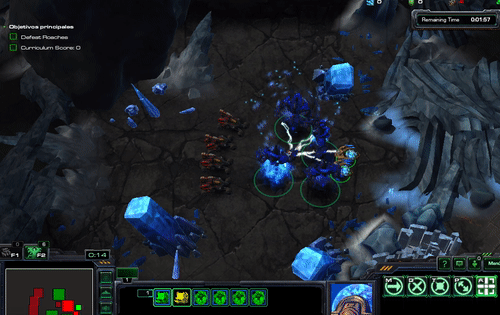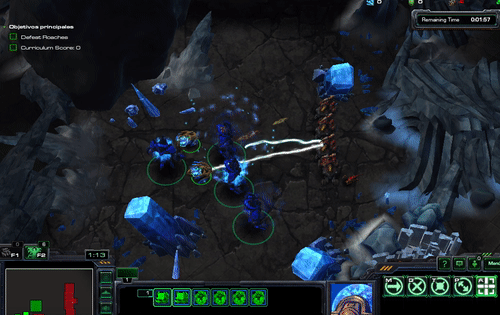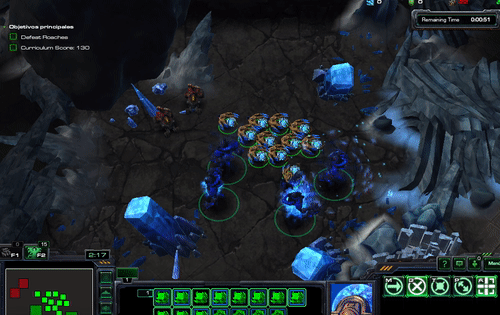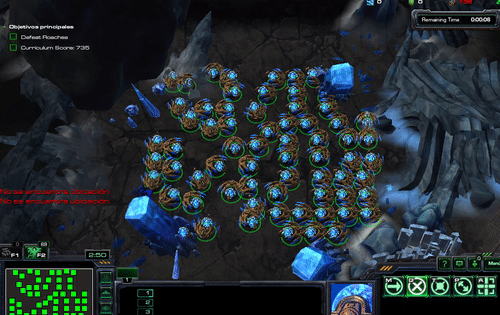
Figure. excrept from Gema Parreño’s blog, StarCraft II Learning environment - running the Hallucination Archon scripted agent
Installation
We need to install the required packages from requirements.txt; however, comment out the package as following:
- Install
pysc2from our customized source - Install
keras-contribfrom source, download from here https://github.com/keras-team/keras-contrib
# PySC2==2.0
numpy==1.14.0
Keras==2.2.2
Keras-Applications==1.0.4
# keras-contrib==2.0.8
Keras-Preprocessing==1.0.2
keras-rl==0.4.2
pandas==0.22.0
Install keras-contrib from source by,
cd keras-contrib
python setup.py install
After doing the previous mini_games.py modification, you can install the pysc2 manually from source
cd pysc2
python setup.py install
You can test the installation with the added mini-games by
python -m pysc2.bin.agent --map HallucinIce
You can test the new mini-games bot agents from scripted_agent_test.py by
python -m pysc2.bin.agent --map HallucinIce --agent pysc2.agents.scripted_agent_test.HallucinationArchon
AlphaStar the Next Level?
- Ref: DeepMind’s AlphaStar Team, AlphaStar: Mastering the Real-Time Strategy Game StarCraft II, Jan 2019. https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
- Ref: Dave Gershgorn, DeepMind’s StarCraft Bot Has a 191-Year Head Start on Humanity, Oct 2019. https://onezero.medium.com/deepminds-starcraft-bot-has-a-191-year-head-start-on-humanity-4590032b23ab
While learners focusing on using the SC2LE to understand smaller scale minigame reinforcement learning, the DeepMind AlphaStar Team has successfully scale-up to train an AI to defeat a top professional StarCraft II player. In a series of test matches held on December 2018, AlphaStar decisively beat Team Liquid’s Grzegorz “MaNa” Komincz, one of the world’s strongest professional StarCraft players, 5-0.
Watch the “AlphaStar: The inside story”
AlphaStar uses a novel multi-agent learning algorithm. The neural network was initially trained by supervised learning from anonymised human games released by Blizzard. This allowed AlphaStar to learn, by imitation, the basic micro and macro-strategies used by players on the StarCraft ladder.
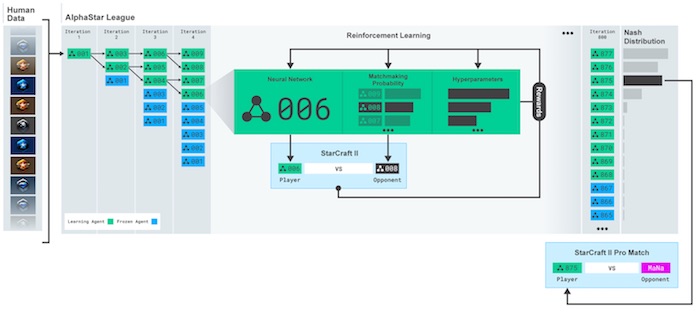
Figure. excrept from the AlphaStar Team blog post showing how the multi-agent reinforcement learning process is created.
Subsequently, these were then used to seed a multi-agent reinforcement learning process. A continuous league was created, with the agents of the league - competitors (AI) - playing games against each other, akin to how humans experience the game of StarCraft by playing on the StarCraft ladder. New competitors were dynamically added to the league, by branching from existing competitors; each agent then learns from games against other competitors. This new form of training takes the ideas of population-based and multi-agent reinforcement learning further, creating a process that continually explores the huge strategic space of StarCraft gameplay, while ensuring that each competitor performs well against the strongest strategies, and does not forget how to defeat earlier ones.
Looks like the new level of AI using deep reinforcement learning is promising!
More References
- David Silver, Reinforcement Learning, a series of 10 youtube video lectures https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLzuuYNsE1EZAXYR4FJ75jcJseBmo4KQ9-
- This is valuable if you are new to RL and want to understand the mathematical and philosophical background to Reinforcement Learning.
- Richard Sutton and Andrew Barto, Reinforcement Learning: An Introduction, MIT Press, 2017, ISBN:9780262193986
- This book provides a clear and simple account of the key ideas and algorithms of reinforcement learning. Their discussion ranges from the history of the field’s intellectual foundations to the most recent developments and applications.
- Rowel Atienza, Advanced Deep Learning with Keras, Packt Publishing, 2018, ISBN:978788629416
- Chapter 9: Deep Reinforcement Learning





