artwork by Style of Kandinsky's TransverseLine transfer to food images
YOLO for Real-Time Food Detection
Food Detection
Part 3 of 3The obsession of recognizing snacks and foods has been a fun theme for experimenting the latest machine learning techniques. The highest goal will be a computer vision system that can do real-time common foods classification and localization, which an IoT device can be deployed at the AI edge for many food applications.
The Snack Watcher in the previous post Snack Watcher using Raspberry Pi 3,
which is using the classical machine learning techniques on the extracted image features, the recognition results are far from impressive. Due to the difficulty of hand-crafted features are affected by background objects, lightings, object position in space and object category variations. In order to reduce the error rate, the environment is required to be fine-tuned; subsequently, the environment assumptions become unrealistic that cannot be deployed in real-life settings.
With the latest improvement on Convolutional Neural Network (CNN), the image classification accuracy has been leaps and bounce in recents years (since 2014). In many instances, AI can recognize objects better than human expert. As a food detection’s technologist, the Deep Learning method is the future of food watching.
The usual difficulty with the Deep Learning is the requirement of a large dataset. Instead of investing great labor to collect the required food images,
I have located the Food100 dataset UEC FOOD 100 (from Food Recognition Research Group at The University of Electro-Communications, Japan) contains 100-classes of food photos. Each food photo has a bounding box indicating the location of the food item in the photo. This is a perfect dataset to replace Snack Watcher to the all-encompassing Food Watcher.

Even though most of the food classes in this dataset are popular foods in Japan, with Toronto’s international food culture, we don’t have a hard time to recognize most of the classes, such as “green salad”, “hot dog” and “hamburger”. The training result should still be interesting in our western culture.
Here is the result of YOLO Real-Time Food Detection on a 720p video stream, running on a Nvidia GTX TitanX, is ~70 fps!
Continue reading this article to understand, setup and train a custom YOLO Neural Network to achieve this result.
[2024/10/05] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/yolo-for-real-time-food-detection/Podcast_YOLO_Food_Detection.mp3
YOLO Real-Time Object Detection
Before explaining the latest and greatest YOLO object detection, it is worth to understand the evolution of object detection to appreciate the contribution of YOLO.
Image Classification
The image classification is given an input image, presenting to CNN, predicts a single class label with the probability that described the confidence that the prediction is correct. The class with the highest probability is the predicted class. This class label is meant to characterize the contents of the entire image; it does not localize where the predicted class appeared in the image.
For example, given the input image in Figure below (left), our CNN has labeled the image as “hot-dog”.

Object Detection
As for object detection, builds on top of image classification and seeks to localize exactly where in the image each object appears.
When performing object detection, given an input image, we wish to obtain:
- A list of bounding boxes, or the (x, y)-coordinates for each object in an image
- The class label associated with each bounding box
- The probability/confidence score associated with each bounding box and class label
Figure above (right) demonstrates an example of performing Deep Learning object detection. Notice how the “hamburger” and “french-fries” are separately classified and localized with bounding boxes.
Therefore, object detection is the additional algorithmic complexity on top of image classification.
Real-Time Object Detection
In addition to object detection, the ultimate challenge is how fast the detection can be done. To reach acceptable “real-time” performance, the expectation is at least 15 fps (frames per second), i.e. running the object classification and localization at ~67 ms per image.
Hello, Darknet’s YOLO
For the longest time, the detection systems repurpose classifiers or localizers to perform object detection. They apply the model to an image at multiple locations and scales. High scoring regions of the image are considered detections.
Thanks to Joseph Redmon’s Darknet implementation https://pjreddie.com/darknet/yolo/, YOLO uses a totally different approach. It applies a single neural network to the full image. This network divides the image into regions and predicts bounding boxes and probabilities for each region. These bounding boxes are weighted by the predicted probabilities. Interest reader should study the original “You Only Look Once: Unified, Real-Time Object Detection” paper https://arxiv.org/abs/1506.02640. This is definitely refreshing to see the implementataion written in C language, still the performance king.
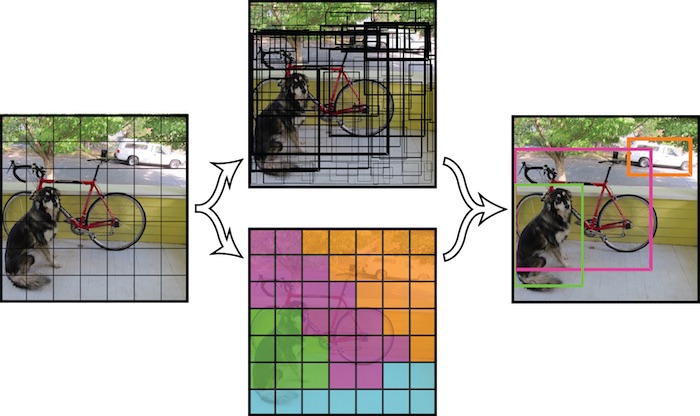
YOLO model takes the whole image at test time so its predictions are informed by global context in the image. It also makes predictions with a single network evaluation unlike systems like R-CNN which require thousands evaluation for a single image. This makes YOLO extremely fast, running in real-time with a capable GPU.
Real-Time Food Detection
We shall train a customized YOLO Neural Network using Darknet with the Japanese Food100 dataset! The Food Watcher will become the most advanced AI which can recognize the common food in real-time. Hopefully, AI will show more sympathy with human needs of these beautiful carbohydrate compounds (aka. food).
YOLO Training
The following instructions concentrated on describing YOLO v2 setup and training. First of all, you need download and install Darknet https://pjreddie.com/darknet/install/.
A very similar procedure for YOLO v3, with some configuration difference. We shall not confuse the discussion in this article.
To get Darknet YOLO training to work, we needs
- Object bounding box file for each image
- Class name file for all the category names
- Training dataset file for the list of training images
- Validating dataset file for the list of validating images
- Configuration file for YOLO neural network specification
- Data location file for finding all the data information
Here is my github https://github.com/bennycheung/Food100_YOLO_Tools of tools to help, check them out if in doubt! It also contains my configuration .cfg, class name .names and data location .data files described later.
They are designed or modified to work with Darknet requirements for bounding box and training data.
food100_generate_bbox_file.py- python script to take each of the Food100 class image directorybb_info.txtand create individual bbox files.food100_split_for_yolo.py- python script to split all Food100 class images into (1)train.txttraining image list and (2)test.txtvalidating image list.food100_tk_label_bbox.py- python script using UI to help drawing bbox associating with the images.
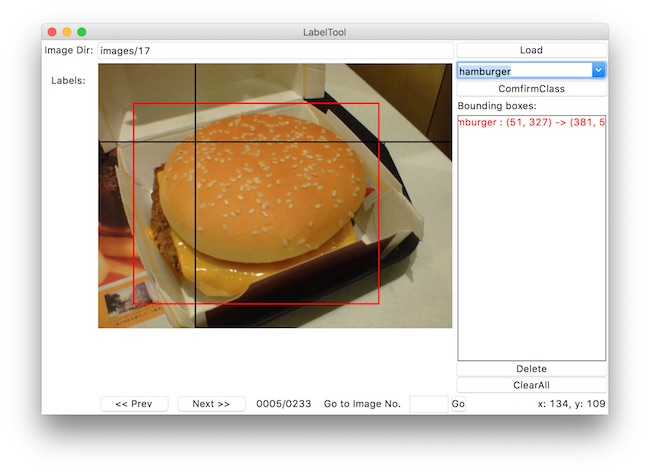
Object Bounding Box File
After downloaded and unpacked the Food100 dataset UEC FOOD 100, it requires post processing to make bounding box that fit into Darknet’s YOLO training requirements.
The Food100 classes are like,
| food_id | name |
|---|---|
| 1 | rice |
| 2 | eels_on_rice |
| 3 | pilaf |
| 4 | chicken-n-egg_on_rice |
| 5 | pork_cutlet_on_rice |
| 6 | beef_curry |
| 7 | sushi |
| … | up to 100 classes |
Bounding Box Class Number
Darknet YOLO (both v2 and v3) expected the class number is 0 based, that the food_id-1 to get the class number
[object-class-id] [center-X] [center-Y] [width] [height]
Originally, I forgot to subtract 1 for the [object-class-id]; that’s make me thinking the training is broken! After re-align to 0 based [object-class-id], the detection shows correct results.
Bounding Box Description File
Darknet YOLO expected a bounding box .txt-file for each .jpg-image-file - in the same directory and with the same name, but with .txt-extension, and put to file: object number and object coordinates on this image.
If we named our food100 image directory as images, then Darknet will automatically look for the corresponding .txt in labels directory. For example, images/1/2.jpg will look for corresponding label in labels/1/2.txt file. I like this approach because we can keep the editing bbox in images/1/2.txt, while the labels/1/2.txt is the bbox format required for YOLO training.
Bounding Box Coordinate in Image
For each food class directory, there is a bb_info.txt that contains all the bbox for every image files. The original bbox is specified as,
[image-number] [top-left-X] [top-left-Y] [bottom-right-X] [bottom-right-Y]
However, YOLO expected each .jpg-image-file has a corresponding bbox description .txt-extension file. The bbox description file is specified as,
[object-class-id] [center-X] [center-Y] [width] [height]
fields are specified by,
- [object-class-id] - integer number of object from 0 to (food_id-1)
- [center-X] [center-Y] [width] [height] - float values relative to width and height of image, it can be equal from (0.0 to 1.0]
- for example: [x] = [absolute_x] / [image_width] or [height] = [absolute_height] / [image_height]
- attention: [center-X] [center-Y] - are center of bounding box (are not top-left corner)
Data Location File
The data file to tell where to find the training and validation paths, food100.data
classes = 100
train = /Users/bcheung/dev/ML/darknet/data/food100/train.txt
valid = /Users/bcheung/dev/ML/darknet/data/food100/test.txt
names = /Users/bcheung/dev/ML/darknet/data/food100/food100.names
backup = backup
- classes = 100 is the number of classes, should equal to line counts of class name file
- train = [path] is the file list of all training images, one image per line
- valid = [path] is the file list of all validating images, one image per line
- names = [path] is the file that list class names
- backup = [path] is where the intermediate
.weightsand final.weightsfiles will be written
Obviously, change the data [path] to your specific data locations.
Traning Dataset File
The train.txt file list of all training images, one image per line. For example,
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6164.jpg
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6170.jpg
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6158.jpg
...
There should be no image coming from the validating dataset.
Validating Dataset File
The test.txt file list of all validating images, one image per line. For example,
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6990.jpg
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6149.jpg
/Users/bcheung/dev/ML/darknet/data/food100/images/61/6099.jpg
...
There should be no image coming from the training dataset.
Class Name File
The class names specified in, food100.names
Subsequently, the class id is 0-based, i.e. rice is class 0.
There is no class-id, just names in this file.
rice
eels-on-rice
pilaf
chicken-n-egg-on-rice
pork-cutlet-on rice
beef-curry
sushi
...
Configuration File
We need to create a configuration file yolov2-food100.cfg.
You can copy darknet
cfg/yolov2-voc.cfgand make modifications
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
...
The meaning of batch and subdivisions is how many mini batches you split your batch in.
- batch=64, loading 64 images for this “iteration”.
- subdivision=8, split batch into 8 “mini-batches”, so 64/8 = 8 images per “minibatch” and this get sent to the GPU for process.
That will be repeated 8 times until the batch is completed and a new iteration will start with 64 new images. When batching you are averaging over more images, the intent is not only to speed up the training process but also to generalise the training more. If your GPU have enough memory you can reduce the subdivision to load more images into the GPU to process at the same time.
Further editing to the configuration file classes and filters specifications,
# number of filters calculated by (#-of-classes + 5)*5
# e.g. (100 + 5)*5 = 525
edit to line 237: filters=525
edit to line 244: classes=100
Darknet Training
For training we use convolutional weights that are pre-trained YOLO on Imagenet. We use weights from the Extraction model.
You can just download the weights for the convolutional layers darknet19_448.conv.23 from YOLO authors website.
wget https://pjreddie.com/media/files/darknet19_448.conv.23
Then, we can start training the customized Darknet’s YOLO by, (change paths to your files location)
./darknet detector train data/food100/food100.data data/food100/yolov2-food100.cfg data/darknet19_448.conv.23
The training log looks like,
...
Loaded: 0.000042 seconds
Region Avg IOU: 0.833301, Class: 0.427628, Obj: 0.624505, No Obj: 0.004012, Avg Recall: 1.000000, count: 7
Region Avg IOU: 0.704510, Class: 0.390626, Obj: 0.270502, No Obj: 0.003151, Avg Recall: 0.875000, count: 8
Region Avg IOU: 0.749244, Class: 0.420920, Obj: 0.444735, No Obj: 0.003990, Avg Recall: 1.000000, count: 8
Region Avg IOU: 0.748636, Class: 0.649185, Obj: 0.626328, No Obj: 0.003061, Avg Recall: 1.000000, count: 8
Region Avg IOU: 0.718167, Class: 0.590265, Obj: 0.568300, No Obj: 0.003715, Avg Recall: 1.000000, count: 8
Region Avg IOU: 0.798298, Class: 0.615076, Obj: 0.464930, No Obj: 0.004568, Avg Recall: 1.000000, count: 8
Region Avg IOU: 0.727497, Class: 0.273119, Obj: 0.348449, No Obj: 0.004568, Avg Recall: 0.875000, count: 8
Region Avg IOU: 0.767684, Class: 0.285230, Obj: 0.376508, No Obj: 0.003249, Avg Recall: 0.875000, count: 8
9998: 5.413931, 5.206974 avg, 0.000010 rate, 2.222207 seconds, 639872 images
...
Usually the network requires 2000 iterations for each class (object), i.e. 100 food classes will need 100 x 2000 = 200000 iterations. But for a more precise definition when you should stop training, use the following heuristics (rule of thumbs):
During training, you will see varying indicators of error, and you should stop when no longer decreases 0.XXXXXXX avg:
Region Avg IOU: 0.767684, Class: 0.285230, Obj: 0.376508, No Obj: 0.003249, Avg Recall: 0.875000, count: 8
9998: 5.413931, 5.206974 avg, 0.000010 rate, 2.222207 seconds, 639872 images
- 9998 - iteration number (number of batch)
- 0.767684 avg - average loss (error) - the lower, the better
When you see that average loss 0.xxxxxx avg no longer decreases at many iterations then you should stop training.
Testing YOLO Food Detection
Before running the test, make sure editing the configuration yolov2-food100.cfg file to use batch and subdivisions to 1 image.
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=8
...
To test the food detector with a test images, run in test mode by,
./darknet detector test data/food100/food100.data data/food100/yolov2-food100.cfg backup/yolov2-food100_final.weights My_amazing_food.jpg
The food100 YOLO v2 testing results are quite impressive which detect wide range of food classes correctly,
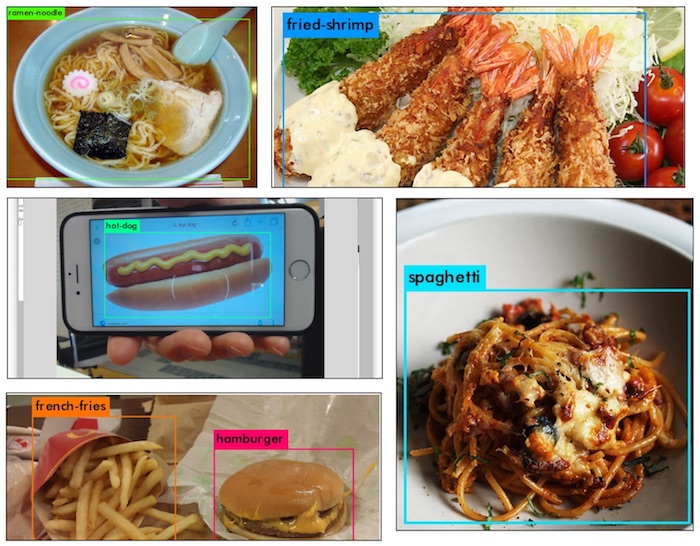
Food Detection with WebCam
To run a real-time food detector, hooking up the webcam and execute demo mode of Darknet,
./darknet detector demo data/food100/food100.data data/food100/yolov2-food100.cfg backup/yolov2-food100_final.weights
Food Detection with Video File
If you have a video file e.g. .mp4, you can stream the video to the real-time food detector in demo mode by,
./darknet detector demo data/food100/food100.data data/food100/yolov2-food100.cfg backup/yolov2-food100_final.weights My_amazing_food_video.mp4
You can also lower the detection threshold by -thresh option, where 0.3 is 30% confidence
./darknet detector demo data/food100/food100.data data/food100/yolov2-food100.cfg backup/yolov2-food100_final.weights -thresh 0.3 My_amazing_food_video.mp4
More Thoughts on Food Detection Results
Here are more interesting results for amuzement,
| Food Detection Case | Description |
|---|---|
 |
Even since the HBO show Silicon Valley released a real AI app that identifies “hotdogs — and not hotdogs”, recognizing hotdog is the golden test standard for any food detection. |
 |
Recognizing ham in a burger - when the ham is not necessary inside the bread, even with a close up view. YOLO can see that is a burger |
 |
Recognizing soupy things - when the food is presented in a soup form. The submerged content did not confuse the YOLO. |
 |
The egg-sunny-side-up with a smiley face cannot hide from the detector. The cut up beef-steak is still detected. Nothing can hide from the AI perceptive power. |
 |
It understands what is a pizza against a pizza-toast. May be the AI can tell the difference by the shape. |
That’s all for now, AI does enjoy the food watching! …
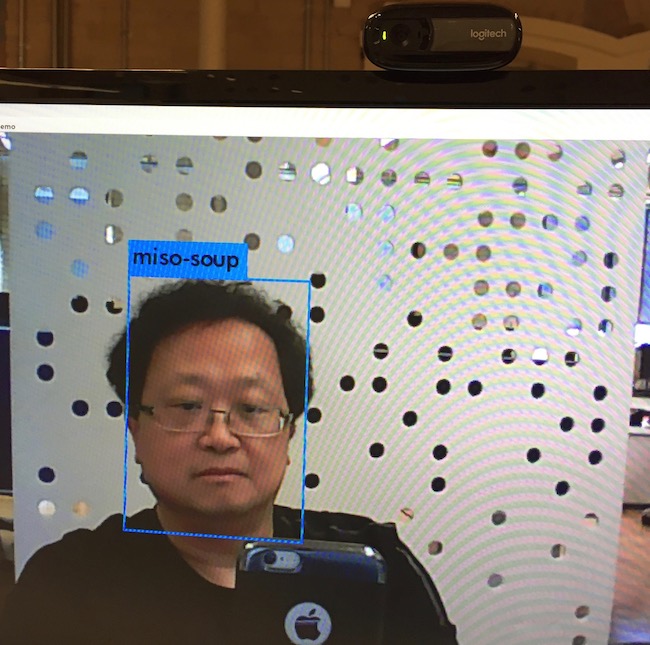
But I did not realize AI is dangerous until it thinks that I’m “food”. :)
References
- Joseph Redmon, his very fast Darknet implementation in C language
- Nils Tijtgat, his detail instructions on YOLO v2 training helps greatly
- Adrain Rosebrock, his excellent tutorials on many Python computer vision projects
- Food Recognition Research Group at The University of Electro-Communications, their hardwork of collecting all the food images and bounding boxes
- Jonah Group, their supportive culture on AI innovations and hardwares




