artwork by Stable Diffusion
Lean AI - How to Reduce LLM Cost?
In the blooming field of Generative AI (GenAI), startups are proliferating like wildflowers after a spring rain. The statistics are staggering, with a veritable boom in the last year alone. But amidst this growth, a pressing question looms: how do we steer these GenAI products towards business success? It’s akin to navigating a ship through treacherous waters, where mastery of domain knowledge, an innovative concept, and effective cost management are the stars by which we must set our course..
[2024/10/04] We can listen to this article as a Podcast Discussion, which is generated by Google’s Experimental NotebookLM. The AI hosts are both funny and insightful.
images/lean-ai-reduce-llm-cost/Podcast_Lean_AI.mp3
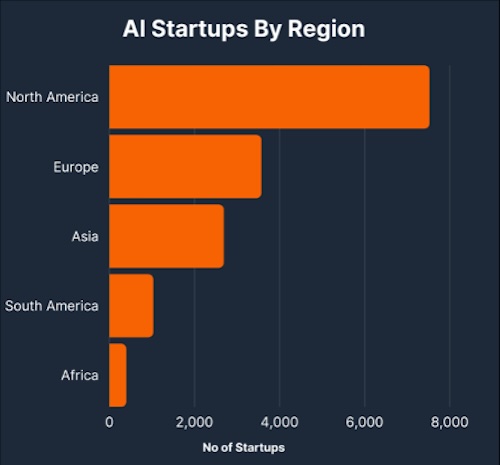
Figure. In 2023, North America alone boasted an impressive tally of over 7,000 AI startups. (image from AI startup 2023 statistics)
We cannot predict which ventures will survive for the next two years, it is clear that a few startups will stand out flawlessly by aligning crucial business elements. These trailblazers are poised for remarkable growth in the foreseeable future, their success underpinned by distinctive product innovations that effectively address significant challenges within niche markets, coupled with their capability to manage operational costs and secure profitable outcomes.
We often focus on the biggest, fastest, and most capable LLMs. However, when it comes to business, cost savings are almost always at the forefront of business leaders’ minds. The concern is how we can reap the benefits of AI while keeping costs reasonable for an organization. Whether you’re a tech leader aiming to streamline operations or a developer interested in the economical aspects of AI, this article is well worth your time.
- [
</style>
](#-include-open-embedhtml-)
- Evolving LLM Features
- Cost Awareness
- Cost Estimation
- Cost Optimization
- 1. Fine-tuning - for specialized task
- 2. Cascade models - for efficiency
- 3. Model Router - for task distribution
- 4. Input Compression - for processing input data
- 5. Memory Optimization - for conversation
- 6. Model Quantization - for lower GPU cost
- 7. Agent-call Cache - for cost reduction
- 8. Lean Components - for optimized input/output tokens
- Methods Adoption
- GenAI Service Platform
- Concluding Remarks
- References
Evolving LLM Features
The evolution of Large Language Models (LLMs) is a tale of rapid advancement, democratization, and specialization. With half a million models now on Huggingface, an open-source repository for shared models, algorithms, and datasets, the landscape is rich with potential. Yet, for business leaders, this fast-paced environment is a double-edged sword. Keeping abreast of new features and ensuring tech debt doesn’t accumulate is akin to running a marathon at a sprinter’s pace. Model maintenance and upkeep become the key to longevity.
Business Leaders need to keep up with these features and how to capitalize on them - tech debt will come quickly - model maintenance and upkeep is the key
- Longer Context Window: Expand to potentially over 1 million tokens for in-depth analysis of large data.
- Advanced Reasoning Capabilities: Enhance reliability and accuracy in responses for broader industry application.
- Improved Inference Speed and Latency: Aim for quicker responses for smoother, natural interactions.
- Increased Memory Capabilities: Advance memory retention for coherent long-term interactions.
- Enhanced Vision Capabilities: Improve image and video analysis tools for cost-efficiency.
- Multimodality: Boost handling of various inputs (text, images, audio, video) for diverse applications.
- Increased Personalization: Tailor responses using individual user data for customized interaction.
Consider the features that are shaping the future of LLMs, these are but a few of the advancements that promise to redefine our interactions with technology. Yet, with great power comes great responsibility—and cost to be tamed.
Cost Awareness
With the knowing of the LLM future and desirable features in our product, choosing the right LLM is a balancing act. We must weigh time to market against accuracy and quality, performance against cost and scalability, and privacy against the need to protect intellectual property. It’s a delicate dance, where each step must be measured and precise.
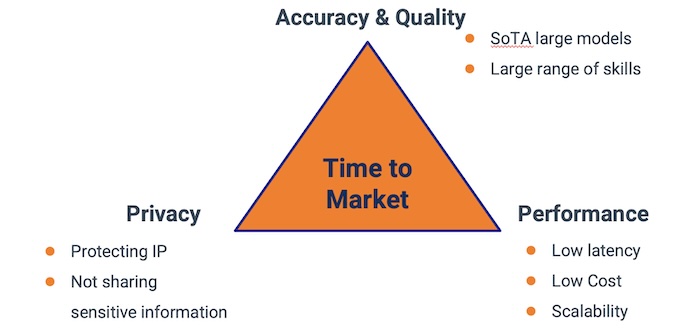
Figure. The triangular framework to represent the critical factors that we must balance, accuracy, performance and privacy.
Let’s use a triangular framework to represent the critical factors involved in selecting the right LLM. At the centre of the triangle is Time to Market underlining the urgency of deployment. Each corner of the triangle highlights a different priority:
- Accuracy & Quality indicated by state-of-the-art (SoTA) large models and a broad spectrum of capabilities.
- Performance characterized by low latency, cost efficiency, and the ability to scale.
- Privacy emphasizing the importance of safeguarding intellectual property and refraining from disclosing sensitive information.
We understand the cost of LLMs is not fixed; it’s as variable as the weather. To navigate these shifting sands, we must understand the forces at play: accuracy, performance, and privacy. Balancing these forces is crucial for timely market delivery without compromises. It’s about knowing which levers to pull—and one such controllable lever, that we inspect in greater details, is about cost reduction.
Cost Estimation
Continue with our analogy on predicting the weather, cost estimation of LLMs is complex and multifaceted. From simple question-and-answer interactions to sophisticated prompt engineering and multi-agent interactions solving complex problems, the token consumption can spiral out of control. Understanding token economics is the first step towards cost-effective AI use.

Figure. The illustration highlights that with the growing complexity of AI interactions, from simple dialogues to elaborate multi-agent systems, token consumption can escalate, necessitating a strategic approach to manage costs.
The use of tokens in AI interactions can increase significantly, pointing out the need to understand token economics for cost-effective AI usage.
- Question & Answer - shows that complex queries necessitate longer, more detailed responses, thus consuming more tokens, especially as follow-up questions or clarifications are required.
- More Tokens for Prompt Engineering - illustrates that creating prompts to generate specific outputs or to direct the AI’s response involves crafting longer and more detailed instructions, leading to greater token use.
- RAG More Context - refers to systems like Retrieval-Augmented Generation (RAG) that incorporate additional tokens to provide context from external sources, increasing the token count; implementing steps for quality and alignment with user intent also adds tokens to the process.
- Multi-Agents Collaboration - depicts scenarios where multiple AI agents collaborate to solve problems or generate a response, with each exchange between agents consuming tokens, especially in systems where outputs from one agent serve as inputs for another, creating a feedback loop.
All these factors contribute to a trajectory where token usage is expected to scale with the capabilities of LLMs. To manage this, an in-depth understanding of token economics becomes crucial. Businesses and developers will need to prioritize efficiency in design and execution to ensure that the increased token usage does not lead to prohibitive costs, thereby ensuring that the progression towards more advanced AI remains both sustainable and accessible.
Tokenization - the Unit of Measurement
Tokenization is a fundamental process in the functioning of Large Language Models (LLMs), where models convert words into tokens, essentially breaking down text into manageable pieces for the AI to process. Typically, one token is equivalent to around four characters, meaning that a single word is approximately equivalent to 1.5 tokens on average. The usage of LLMs is measured by these tokens, creating a direct impact on how we use and pay for AI services. Most LLM APIs are priced per million tokens, for example GPT4 is ~30.00 USD/1M tokens while Llama2-70b is ~2.00 USD/1M, making tokenization a critical factor in both usage metrics and pricing structures.
Tokenization is the measuring stick for LLM usage and pricing. Not all tokenizers are created equal; they convert words to tokens with varying efficiency. By mastering token economics, we unlock the door to find the most cost-efficient AI solutions.
Cost Observability
The role of monitoring these systems for cost inefficiencies can be likened to having a lookout at the masthead, ever vigilant, scanning the horizon for ways to streamline our journey and ensure it’s not only groundbreaking but also cost-effective.
Enter tools like LangSmith and LLMStudio. These are the telescopes through which our lookout peers, offering a clearer view of our AI spend. With these instruments, we’re not just reacting to the waves of expenses as they crash over the bow; we’re anticipating them, steering a course that avoids unnecessary expenditure without sacrificing the speed of innovation.
Identifying inefficiencies in our AI operations is akin to spotting a storm on the horizon. With early detection, we can adjust our sails, make necessary course corrections, and continue on our path, not just with prudence but with precision. Implementing changes to foster cost-effective operations is not merely a matter of financial stewardship; it’s an essential strategy for sustainable innovation.
Cost Optimization
After establishing the foundation in our previous discussion, let us explore the eight methods of cost optimization:
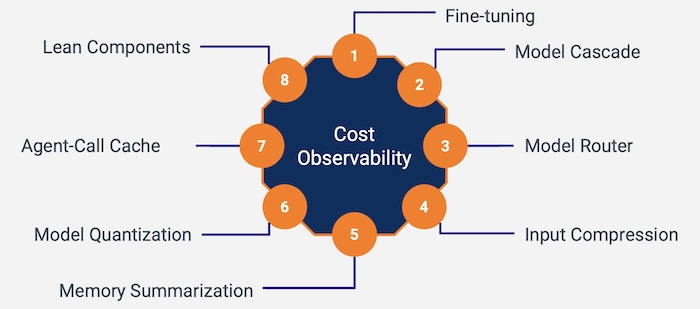
Figure. With the foundation of cost observability and cost metrics, we shall layout the 8 cost optimization methods.
The list of the 8 cost optimization methods:
- Fine-tuning: Tailoring a pre-trained LLM using a substantial amount of task-specific data to enhance performance for specialized tasks.
- Model Cascade: Implementing a tiered approach using simpler models to handle basic tasks and escalating to more complex models as needed for efficiency.
- Model Router: Distributing tasks to the most appropriate models to handle their complexity, ensuring intelligent routing of queries.
- Input Compression: Preprocessing input data to reduce size and complexity before it reaches the LLM, saving on token usage and computational costs.
- Memory Summarization: Optimizing conversational memory in chatbots by summarizing past interactions to manage memory load efficiently.
- Model Quantization: Reducing the precision of LLM parameters to decrease computational demands, allowing for lower costs and faster processing.
- Agent-Call Cache: Using a system of caching responses from multi-agent collaborations to reduce the need for repetitive computation, thereby saving costs.
- Lean Components: Streamlining AI components to reduce unnecessary token consumption, optimizing the input/output process.
1. Fine-tuning - for specialized task
Starting with a powerful model to launch a product seems like overkill, doesn’t it? It’s like using a sledgehammer to crack a nut. But there’s method in this madness. The idea is to use this initial phase as a data collection exercise. You’re essentially setting up a wide net to capture as much relevant data as possible. This data, which includes user feedback on what’s working and what isn’t, becomes the goldmine for the next crucial step: fine-tuning.

Figure. The process of LLM fine-tuning, where a pre-trained LLM is enhanced using gigabytes to terabytes (GB-TB) of task-specific labeled examples, shown as prompt-completion pairs, to create a fine-tuned LLM with improved performance for specific tasks.
Fine-tuning is where the magic happens. It’s a process that sounds technical, and indeed it is, but at its core, it’s about making something more suitable for its purpose. Imagine taking a generalist—a jack-of-all-trades—and giving them the tools and knowledge to become a specialist. That’s what happens when you fine-tune a smaller LLM model like Mistral or Llama 2 with the data collected from the initial phase. These smaller models, now armed with specific insights, can perform tasks with a precision that rivals the original behemoth, GPT-4, but at a fraction of the cost.
The savings are staggering. We’re talking about reducing costs by more than 98% compared to building a foundational model from scratch. However, it’s not a one-size-fits-all solution. Fine-tuning shines in specialized tasks. When you tailor a model to do one thing exceptionally well, it might stumble if asked to step outside its comfort zone. For broad applications like chatbots, which need to handle a wide range of queries, the fine-tuned model might not always hit the mark.
2. Cascade models - for efficiency
The concept of cascade models for efficiency is both simple and ingenious. It’s like having a series of filters, each one designed to catch certain types of problems. The first filter is the simplest, designed to handle the most straightforward tasks. If something passes through it, that means it requires a bit more scrutiny, so it moves on to the next filter, slightly more complex, and so on. This process continues until the task finds its match - a model capable of handling its complexity.
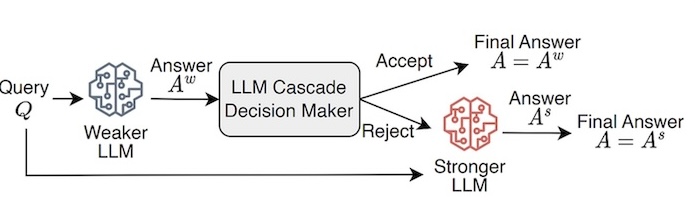
Figure. LLM Cascade Schema (image from the original paper)
Take, for example, a question that needs answering. Initially, it’s directed to a small model, perhaps something lightweight like Mistral. Mistral gives it a go, but if it’s not quite up to the task - indicated by a low confidence score given by LLM Cascade Decision Maker - the question doesn’t just get dropped. Instead, it’s passed up the chain to a more capable model. This escalation continues until we find the Goldilocks zone: not too simple, not too complex, but just right for the question at hand.
This method shines in its cost efficiency. It’s no secret that computational power comes at a price. By starting with less expensive models and only calling in the heavy hitters when necessary, we optimize our resources. We’re not using a sledgehammer to crack a nut; we’re using exactly the right amount of force at every step. In a world where efficiency is key, cascade models offer a smart way to balance cost against computational needs.
3. Model Router - for task distribution
The concept of an LLM router for task distribution is a fascinating development in the field of artificial intelligence. At its core, this approach involves a large language model (LLM) that functions as a gatekeeper, analyzing incoming queries to decide whether they can be addressed by less complex models or if they necessitate the capabilities of more advanced ones. Hugging Face’s implementation of this idea, where an LLM acts as a controller to dissect user queries into smaller, manageable subtasks and then assigns them to specialized models, is a prime example of this innovative strategy in action.
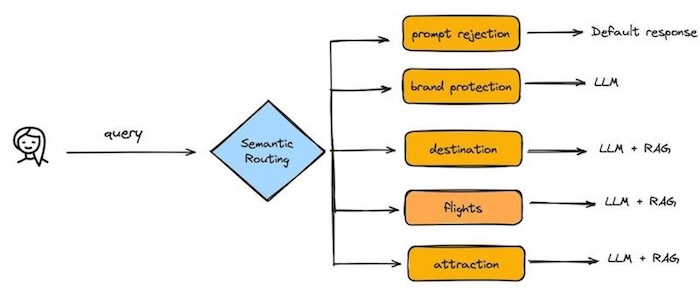
Figure. Imagine a digital travel assistant powered by a Large Language Model (LLM) optimized through semantic routing (image from semantic router library)
The advantages of employing an LLM router for task distribution are significant. By intelligently routing requests to the models best suited for those specific tasks, this method promises not only to enhance the efficiency of processing queries but also to optimize the use of computational resources. This could lead to faster response times and more accurate answers, improving the overall user experience. Moreover, it allows for a more judicious use of powerful models, reserving their capabilities for tasks that genuinely require them, while simpler requests can be efficiently handled by smaller models. This tiered approach to problem-solving in AI could pave the way for more scalable and sustainable AI systems, making advanced AI more accessible and effective across a wider range of applications.
Here’s how a day in the life of such an AI travel assistant might unfold:
A user starts a conversation with the query, “I want to plan a holiday in Greece.” The semantic routing system promptly analyzes the query’s intent and routes it to the appropriate response pathway. If a user’s request doesn’t align with the service’s guidelines, it’s swiftly handled with a default response due to prompt rejection for brand protection. But in this case, the query is valid and is routed towards the “destination” pathway.
As the user conversation continues, AI utilizing both LLM and Retrieval-Augmented Generation (RAG), pulls from vast databases of information to provide a curated list of must-visit spots in Greece. The user inquires about “flights to Athens,” the system routes this to the “flights” pathway. Finally, should the user ask for “top attractions in Athens,” the query is sent down the “attraction” route.
4. Input Compression - for processing input data
When Microsoft introduced LLMLingua, they tackled a problem many hadn’t fully articulated yet: the inefficiency of feeding raw, unprocessed data into complex models. It’s akin to asking someone to find a needle in a haystack without first using a magnet to remove all the metallic chaff. LLMLingua acts as that magnet for data, stripping away the unnecessary, leaving only the essence for the more sophisticated models to examine.
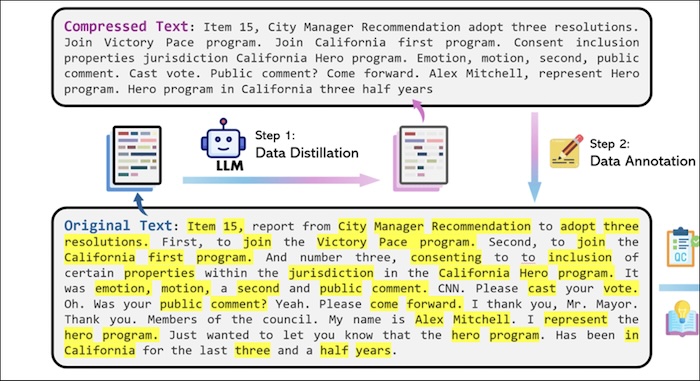
Figure. Illustrate LLMLingua process the original text to extract the important (highlighted) content, producing the compressed text before sending the request to LLM. (image from Microsoft LLMLingua-2: https://llmlingua.com/llmlingua2.html)
This approach is not just about efficiency; it’s a fundamental shift in how we think about processing information. By reducing the number of tokens, LLMLingua doesn’t just save on computational costs; it refines our focus. It forces us to consider what’s truly important in our data before we ask our most powerful tools to analyze it.
See the sample Python code, llmlingua is so simple to use.
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
In applications like summarizing content or isolating specific data points within a vast dataset, LLMLingua proves its worth. It’s a reminder that sometimes, in our quest for more powerful solutions, simplifying the input can be just as innovative. Microsoft’s development here is a lesson in the elegance of efficiency, showing that the path to advanced analysis doesn’t always lie in adding complexity, but often in skillfully reducing it.
5. Memory Optimization - for conversation
When we talk to someone, we don’t remember every word they’ve said. Our brains summarize past conversations, keeping the gist while letting go of the minutiae. This natural process is something chatbot developers are trying to mimic to optimize memory usage in conversation agents.
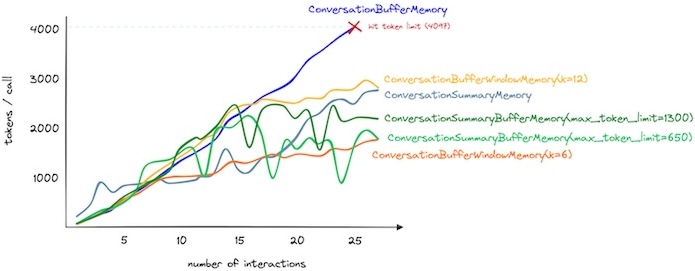
Figure. Illustrates various built-in Conversation Buffer Memory methods, plotting to show the memory consumption against the number of interactions. (image from Jame Briggs, Conversational Memory for LLMs with Langchain, Pinecone blog).
The challenge is straightforward: how can we manage a conversational memory so it doesn’t need to recall every detail of past interactions, yet still generate relevant and coherent responses? Two strategies have emerged as promising solutions: Conversation Summary Memory and Summary Buffer Memory.
Conversation Summary Memory is like having a friend who only remembers the highlights of what you’ve told them. It compresses past conversations into summaries, drastically reducing the amount of data (or tokens) the chatbot needs to hold onto. This approach is akin to how we might tell someone about a book we’ve read, focusing on the main plot points without recounting every scene.
Summary Buffer Memory takes a slightly different approach. It’s like a camera that captures recent events in sharp detail but stores older memories as faded photographs. This method keeps recent conversations accessible in full detail but gradually summarizes older interactions. It’s a balance between retaining useful information and managing memory efficiently.
Both strategies share a common goal: to reduce the memory load on chatbots without compromising the quality of interaction. By adopting these methods, developers can create chatbots that are not only cost-effective but also remarkably human-like in their ability to engage in meaningful conversations. Just as we don’t need to remember every word of a conversation to understand and respond appropriately, chatbots can now do the same, marking a significant step forward in making them more relatable and efficient communicators.
6. Model Quantization - for lower GPU cost
Model quantization shrinks model size and boosts efficiency by reducing precision. In the development of LLMs, has often been seen as a playground for those with access to the most powerful and expensive hardware. The computational demands of these models not only require significant energy but also incur high costs, limiting their accessibility. However, a transformative approach known as quantization is changing the landscape.
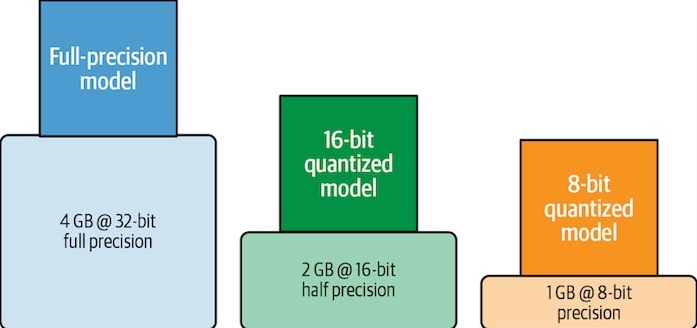
Quantization simplifies the complexity of LLMs by reducing the precision of the numbers it uses. Imagine you’re painting a picture but decide to use a smaller palette of colours. Surprisingly, the essence of the painting remains, but you’ve used less paint and taken less time. Similarly, quantization significantly reduces the size of LLMs and increases their efficiency without sacrificing much in terms of performance.
This reduction in size and increase in speed lead to faster inference times and lower energy consumption. What does this mean for the broader community? It democratizes access to advanced AI technologies. Smaller companies and individuals with less powerful hardware can now experiment with and deploy sophisticated AI models that were previously out of reach.
7. Agent-call Cache - for cost reduction
The concept of multi-agent systems for cost reduction emerges as a beacon of efficiency and pragmatism. Imagine a scenario where tasks are approached not by a single, all-powerful model, but by a team of agents, each with its own specialty and cost. This is not a distant future; it’s a practical solution being implemented today.
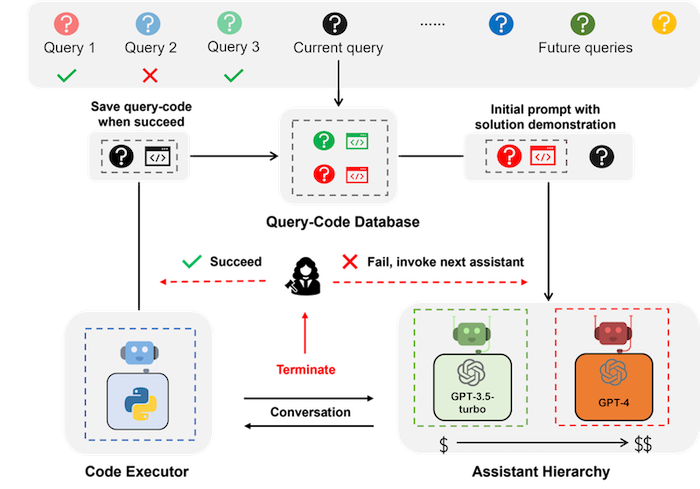
Figure. EcoAssistant: the system involves two agents, one executor agent for executing the code and the other assistant agent backed by LLMs for suggesting code to obtain information and address the user queries. The query-code database stores the previous successful query and code pair. When a new query comes, the most similar query in the database is retrieved and then demonstrated in the initial prompt with the associated code. The conversation invokes the most cost-effective assistant first and tries the more expensive one in the assistant hierarchy only when the current one fails. (image from Autogen Ecoassistant)
At the heart of this approach lies a simple yet profound strategy: start small, then escalate. Tasks are initially assigned to more economical models. Only if these models stumble do we turn to their pricier counterparts. This tiered approach ensures that most tasks are handled efficiently by less expensive agents, reserving the heavy lifters for truly challenging problems.
Consider the EcoAssistant framework, a shining example of this philosophy in action. It tackles the issue of generating accurate code from external queries without breaking the bank. By employing a hierarchy of language model assistants, EcoAssistant optimizes both cost and effectiveness. Initial attempts are made with cheaper models, escalating to more sophisticated ones only as needed. Moreover, by storing successful outcomes, the system self-improves, making cheaper models increasingly capable over time.
8. Lean Components - for optimized input/output tokens
When we think about optimizing tools for input/output tokens, we’re essentially talking about a form of efficiency. It’s about making sure that when we communicate with LLMs, we’re not just throwing everything at them and seeing what sticks. Instead, we’re being thoughtful about the information we send and receive.
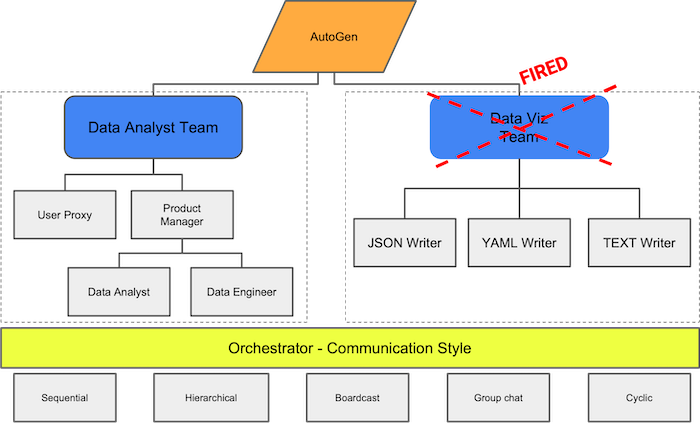
Consider an agents organizational structure divided into two main teams: the Data Analyst Team and the Data Visualization (Data Viz) Team, with the latter marked as “FIRED.” The dismissal of the Data Viz Team is attributed to their inefficiency, notably consuming an excessive number of tokens while performing tasks calling LLM. Their role in generating JSON, YAML, or TEXT outputs has been evaluated as not cost-effective, and the decision has been made to replace their function with simpler, non-LLM based solutions.
The benefits of this approach are twofold. First, it reduces the load on the LLMs. These models are powerful, but they’re also resource-intensive. By lean components, we’re not only saving computational resources but also potentially lowering costs. Second, and perhaps more importantly, this method can improve the quality of the system by focusing on relevant use case to LLM.
In essence, optimizing tools for input/output tokens is about being smart with our resources. It’s a reminder that more data isn’t always better. Sometimes, the key to effective communication with LLMs lies in simplicity and relevance
Methods Adoption
The strategic model outlining eight cost optimization methods designed for AI services, each positioned within a color-coded category based on their readiness for adoption and potential impact on the product: “Defend,” “Differentiate,” and “Upend.”
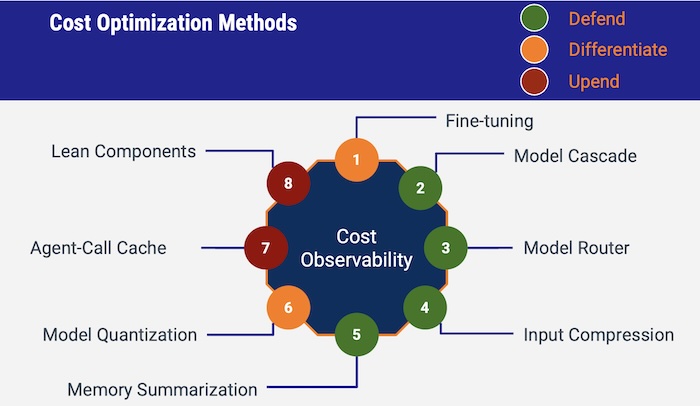
For methods in the “Defend” category, which are essential and relatively easy to implement, we have:
- Model Cascade: Layering models to filter and escalate tasks efficiently, reducing unnecessary processing.
- LLM Router: Dynamically routing queries to the most appropriate models to handle varying demands efficiently.
- Input Compression: Reducing the size of input data to save on processing time and cost.
- Memory Summarization: Condensing information into compact representations to minimize storage and retrieval costs.
The “Differentiate” methods are more challenging but can significantly enhance our product:
- Fine-tuning: Tailoring models to specific tasks to enhance performance without excessive computational overhead.
- Model Quantization: Reducing the precision of model parameters to decrease size and increase inferencing speed without substantial loss of accuracy.
Lastly, in the “Upend” category, which are forward-thinking approaches that could revolutionize the product if we adopt an agentic AI model, we have:
- Agent-Call Cache: Caching previous interactions to speed up response times and reduce repetitive computations.
- Lean Components: Streamlining AI components to the essentials, which can greatly reduce complexity and cost.
Each of these methods represents a different stage in the AI optimization journey, from immediate and actionable (“Defend”) to innovative and potentially industry-disrupting (“Upend”).
GenAI Service Platform
The proposed GenAI service platform designed to provide efficient and intelligent solutions. At the heart of this architecture lies the LLM Router including the model cascade built-in, a dynamic hub that directs incoming user queries to the appropriate resources. This routing is essential for maintaining high performance, ensuring that responses are not just accurate but also delivered promptly, all while minimizing operational costs.
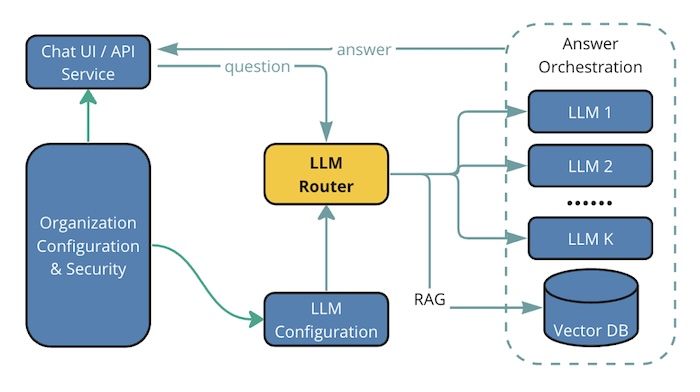
Figure. Illustrate the proposed GenAI service platform which integrated a number of cost optimization methods into a unified solution.
To achieve cost efficiency without compromising the intelligence of the services, the platform incorporates several integrated cost optimization methods. It is equipped to handle a diverse array of user inquiries across various domains, showcasing the flexibility and scalability necessary for a broad range of topics. By maintaining a repository of domain-specific models, the platform can selectively engage the most suitable LLM for a given query, ensuring the responses are of high accuracy and relevance.
Furthermore, the integration with Retrieval-Augmented Generation (RAG) systems and Vector Databases (Vector DB) is crucial. These components work together to optimize resource utilization. The RAG system leverages external knowledge bases to support the LLMs in generating more informed responses, while Vector DB stores and retrieves information efficiently, contributing to the reduction of computational overhead.
This design underlines the objective to not only provide intelligent answers but to do so with an eye toward sustainability. By engaging specialized models only when necessary and using RAG systems for support, the architecture minimizes resource usage and, consequently, the cost. This approach ensures that the AI services remain both top-notch in performance and sustainable in the long term, aligning with our aim for cost-effective intelligence.
Concluding Remarks
When we talk about cost optimizing LLMs, we’re really talking about a series of trade-offs. At the heart of these optimizations—fine-tuning, cascading, and routing, is a balancing act between making these models more efficient and maintaining their effectiveness.
Fine-tuning adjusts an LLM to perform specific tasks better. It’s like sharpening a knife; the process makes the tool more suitable for the job at hand. Cascading, on the other hand, is about filtering questions through a series of increasingly specialized models. Imagine a series of sieves, each finer than the last, ensuring that only the most relevant particles—or in this case, data—get through. Routing directs queries based on their content to the most appropriate processing pathway, akin to a well-organized library where every book has its place, ensuring quick and accurate retrieval.
Then there’s the issue of model quantization—the process of reducing the precision of the model’s calculations to save on computational resources. It’s a bit like compressing a file to save space on your hard drive; you hope the loss in quality isn’t noticeable, but there’s always a trade-off.
As we gain deeper understanding of these cost optimization, we also bump into practical concerns like cost-saving measures and the ever-present of privacy and security. It’s one thing to optimize an LLM; it’s another to do so in a way that doesn’t compromise user data.
You could attach prices to thoughts. Some cost a lot, some a little. And how does one pay for thoughts? The answer, I think, is: with courage.
by Ludwig Wittgenstein, Culture and Value
This journey into LLM optimization isn’t just about technical skill. It’s about daring to experiment, to push boundaries. Ludwig Wittgenstein once pondered the value of thoughts. In the realm of LLMs, it’s clear that our willingness to innovate, to take risks, is what drives progress. As we navigate this complex landscape, it’s our courage to explore new paths that will ultimately define our success
References
Resources
- Martin Keen, The most important AI trends in 2024, IBM Technology, video, 6 Mar 2024.
- Lingjiao Chen, Matei Zaharia, James Zou, FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv:2305.05176 [cs.LG], 9 May 2023.
- Synthetic Intelligence Forum, FrugalGPT: Reduce Cost and Improve Performance of Large Language Models, James Zou, 5 Jun 2023.
- TensorOps, Analyzing the Costs of Large Language Models in Production, video, 6 Dec 2023.
- Jame Briggs, Conversational Memory for LLMs with Langchain, Pinecone blog.
- Greg Kamradt, Workaround OpenAI’s Token Limit With Chain Types, Data Independence video, 1 Mar 2023.
- Dylan Patel and Afzal Ahmad, The Inference Cost Of Search Disruption – Large Language Model Cost Analysis, semianalysis Blog, 9 Feb 2023.
- Jieyu Zhang, et al., EcoAssistant: Using LLM Assistant More Affordably and Accurately, arXiv:2310.03046v1 [cs.SE], 3 Oct 2023.
Tools
- Tokenizer Playground: https://huggingface.co/spaces/Xenova/the-tokenizer-playground
- Microsoft LLMLingua-2: https://llmlingua.com/llmlingua2.html
- Autogen Ecoassistant: https://microsoft.github.io/autogen/blog/2023/11/09/EcoAssistant/
- LangSmith: https://www.langchain.com/langsmith
- Arize Phoenix: https://phoenix.arize.com/